Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
FacebookHow I hacked my own site by feeding it a profile picture via webmention
Two weeks ago I wrote that I hacked my own site. I think it’s important to share how I did it, to make people more aware of possible vulnerabilities, so they can find them too. If others didn’t write about their findings, I wouldn’t have found this one.
I did my best to reach out to people using the same code. If you are using the Kirby Webmentions plugin or my fork of it, please make sure to update!
Webmentions
As some of you may know, my site supports webmentions. In short, this enables me to show replies underneath my posts, that are written by people on their own site. If you write a reply, link to me, mark it up with Microformats and send a webmention, my site fetches your post and shows it as a reply. I use a service called Bridgy to also receive comments from Twitter and Instagram. All of this is automated and very cool.
However, while very cool, it is also potentially dangerous to show external content on your site. The vulnerability I found is an example of what can go wrong.
If you look around on my site, you see I do not only show the content of the reply, but also a picture of the author, if provided. This is especially nice when showing likes:

This nice overview of likes comes from the Kirby Webmentions plugin by Bastian Allgeier, which I modified a bit.
My server takes the fall
In order to protect visitors of my site from other security issues, the plugin downloads the images and shows those downloaded ones. This way my visitors only deal with my server, and not with the servers of everyone who liked my post. It’s a nice service, but it also means that I move the problem: I now have to handle those images with care on my side. My server takes the fall for my visitors.
The problem is: my server just downloads whatever image you give it. In most cases, this will be a nice avatar I can display for my friendly visitors. But one can think of a case where a not-so-friendly visitor feeds my site something else than an image. The plugin of course checks if it’s an image and rejects files that are not a image, but it’s still worth a try.
So, what did you feed it?
Since my server runs on PHP, the nicest thing for an attacker to feed my server is a PHP-file. That way, you can run whatever code you want on my server, doing all kinds of evil things. However, just straight off feeding my site a PHP-file did not work. The plugin is not crazy. It checked wether the MIME of the file was an image of type jpeg, png or gif. It rejected an image.php file like this:
echo "hi!";Using image.jpg as filename would fail too: the plugin saw that the file had no MIME of an image, so it did not download it. This was the point where I went to bed with a feeling of security: my site was safe and I could not get a php-script in.
The next day, however, I had second thoughts. I needed a real image for my new plan, so I took a screenshot of a smiley. I then opened it in notepad and added the following to the bottom of the file:
<?php mail(‘my.email@gmail.com’, ‘Seb’, ‘hi’);I then renamed the file to image.php, because you need the PHP-extension in your file to let the server run your code. The last step was disabling PHP on my test-server, to prevent the test-server from executing the code and send mail me. The code just appeared at the end of the image.
I then made a test-post with a u-like-of set to the URL of a post on my blog, and a p-author h-card with an <img src="/photo.php">. It was a like, with an author and an my bad image.
And it worked.
The server sees the image and checks for the MIME, which was image/jpeg, because it was an image. It then downloaded it, including the un-executed PHP string in the bottom of it. It changed the name of the image into the SHA1-hash of the original image-url, but then it appended the extension of the original file, which was .php!
My server then had a file called a266d629bb26d74752080bb1b95bbd0a488bea53.php, which was linked as an image in my post. Every time I refreshed the page, the snippet of code in the bottom of the file got executed, so it sent an e-mail to me.
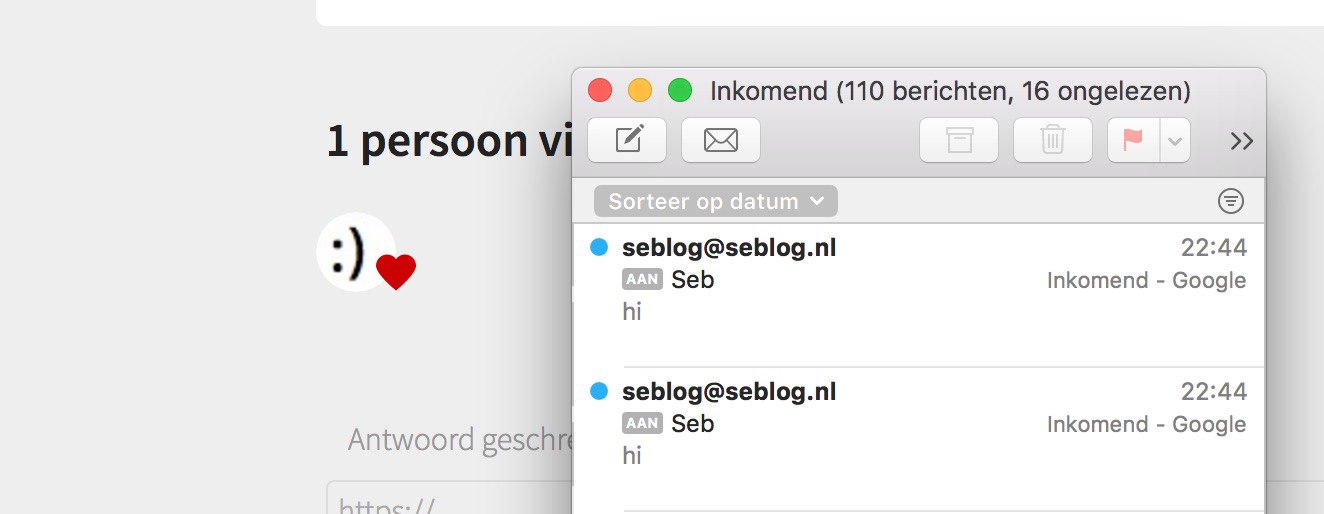
In this example, I sent an e-mail, but it could’ve been anything.
How to solve?
First off: check your input! And then check it again. A crucial thing for PHP-files is that they get executed if they have the .php extension, so you should not rely on user input for that. Change the filename and change the extension.
Bastian updated the plugin, so now it does not only check for MIME, but also only accepts files with the extensions jpg, jpeg, png and gif. Only if it has a correct extension, it downloads the file, and it checks MIME twice, both before and after the download. I think it’s locked down pretty well, although it still feels a bit scary.
Aaron Parecki, who did this way of showing likes first, uses an external service for his webmention images, and that’s not a bad idea either. If someone manages to get in something bad, it’s not on your the same server as your site. It could also be a good idea to turn off PHP for your upload folder, if you have that kind of access to your server.
Final words
I really like this webmention plugin! It’s thanks to this plugin that I know IndieWeb and all the wonderful things it brings.
But while the plugin and IndieWeb are nice, it’s also good to keep and eye on security. At this moment, webmention is relatively safe because not many people know about it or use it. Although it can be a lot of fun to have a post of a friend automatically show up beneath your post, we have to be aware of the risks of showing content of external parties.
So, be warned, and have fun.