Today I did some invisible things. The first does not count for #100daysofindieweb, because it’s too invisible, but the second is valid, I think.
My blog runs on Kirby, which uses .txt files in a folder structure. In order to show you list posts, my server looks at several .txt files. The more posts I post, the more .txt files my server has to open. It all held up quite a while, but since my Twitter import my site contains 8000 pages.
This was not big of a problem for the main page, because I told Kirby to look at the newest folders first, and stop after 20 posts. (They are sorted by date, after all.) But when you want to view only the blogposts, or only posts with a photo, things became slower, because it had to look further in the past. Not to mention what would happen if you ask for a category that does not exist. With 8000 posts, my server would say no.
So I indexed all my posts with a database, a little while ago, and that seemed fine. The only problem was that the database is a pain to maintain. I did add pages to the database when I posted a post via Micropub, but when I edited pages via FTP, I needed to put ?reindex=1 behind the url to trigger a database update for that page. Sometimes you forget that kind of stuff.
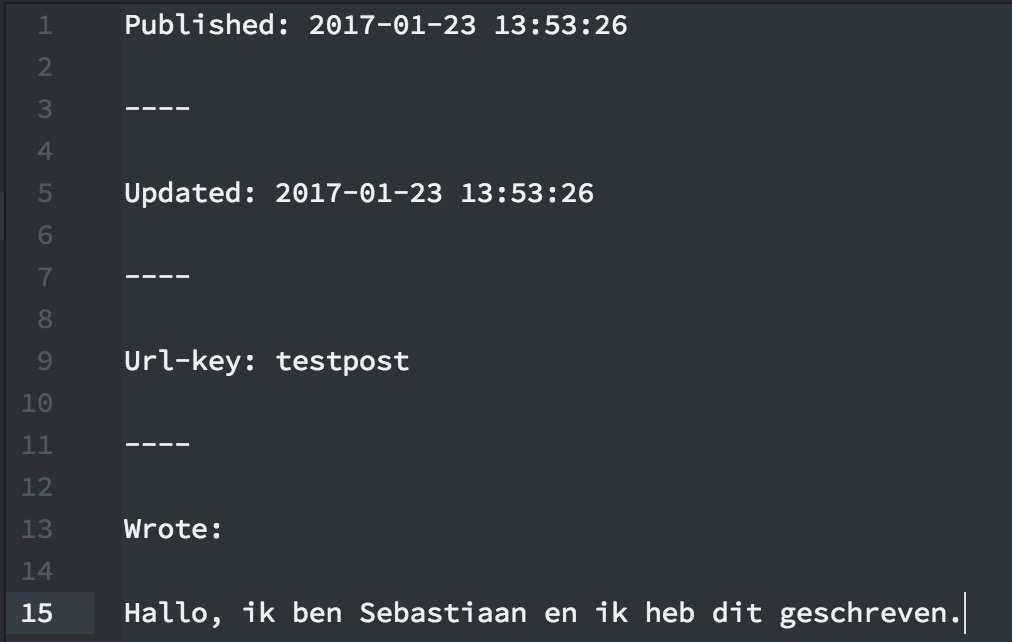
Anyway. Today I made a system where entries are cached. I don’t cache the whole page, I just cache the h-entry, the part in this white block. The page now checks wether a .html version of the entry exists, and also checks the timestamps on the .html, the .txt and the entry.php snippet. If the .html turns out to be current, it shows the .html, and if not, it generates a new .html file and shows that new one.
With this new event, I reindex when the .txt has been updated. I still have to visit the page to trigger a reindex, but it’s much more smooth and almost goes without thinking. I’m very happy with how things turned out.
Unfortunately, all of this is not visible, and I haven’t opensourced this part either. And that’s not how things work in this challenge.
So, I needed to do something more visible for #100daysofindieweb. Yesterday I read about Kevin Marks’s Indiecards, and my site turned out weird on them. The main problem was that Indiecards look for the first h-* element on a page. Before today, the first h-* element on my homepage was a h-feed.
I fixed that today: my homepage now first gives a h-card. My h-entry pages still use that ‘same’ h-card as a p-author. Only my feeds now have a u-author set to /, which translates to https://seblog.nl/, which translates to the h-card on my homepage. More people do this, so I should be fine.

 Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
Facebook