
 Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
Facebook Seb heeft dit gebookmarkt.
Seb heeft dit gebookmarkt."De wereld is een beangstigende plek, maar mijn sokken zijn perfect gevouwen."
Seb heeft dit gebookmarkt.Busy day today, so no big Indieweb updates. It’s not about the big updates though, it’s about useful updates.
Yesterday, I went to an event. I kind of got into the habit of just getting on my bike and cycling to events, without actually looking up any details at home. Sometimes I don’t even know the exact place I need to go, just that it’s somewhere in the city center. It’s a bad habit, but it’s a habit now.
Since I posted an RSVP to my site for yesterdays event, I was able to find the information I was looking for quickly on my phone. I have been away from Facebook for almost 3 years now and I forgot how useful this feature is.
A combined feed of my RSVPs and Events can now be found at /agenda (Dutch for ‘calendar’), so I can easily find information about where I have to go when I’m cycling and running late next time.
 Seb vindt een foto van Jelte Nieuwenhuis leuk.
Seb vindt een foto van Jelte Nieuwenhuis leuk. Seb heeft 272 woorden geschreven.
Seb heeft 272 woorden geschreven.This is a thing I wanted for some time now. Since my weblog is now more a timeline than a blog, long posts disappear fast in the stream of short ones. But since the long posts hold their value longer, I wanted to show them longer.
Also, since I started with this #100daysofindieweb-thingy, I also started to blog in English, which I never did before. My stream of posts gets flooded with English posts.
Today I made a homepage widget. It only shows on the main page, and I can put different parts in it. It now contains a blog list for both Dutch and English, a list of blogposts with #100daysofindieweb, a stream of likes and bookmarks, and the most recent photo post.
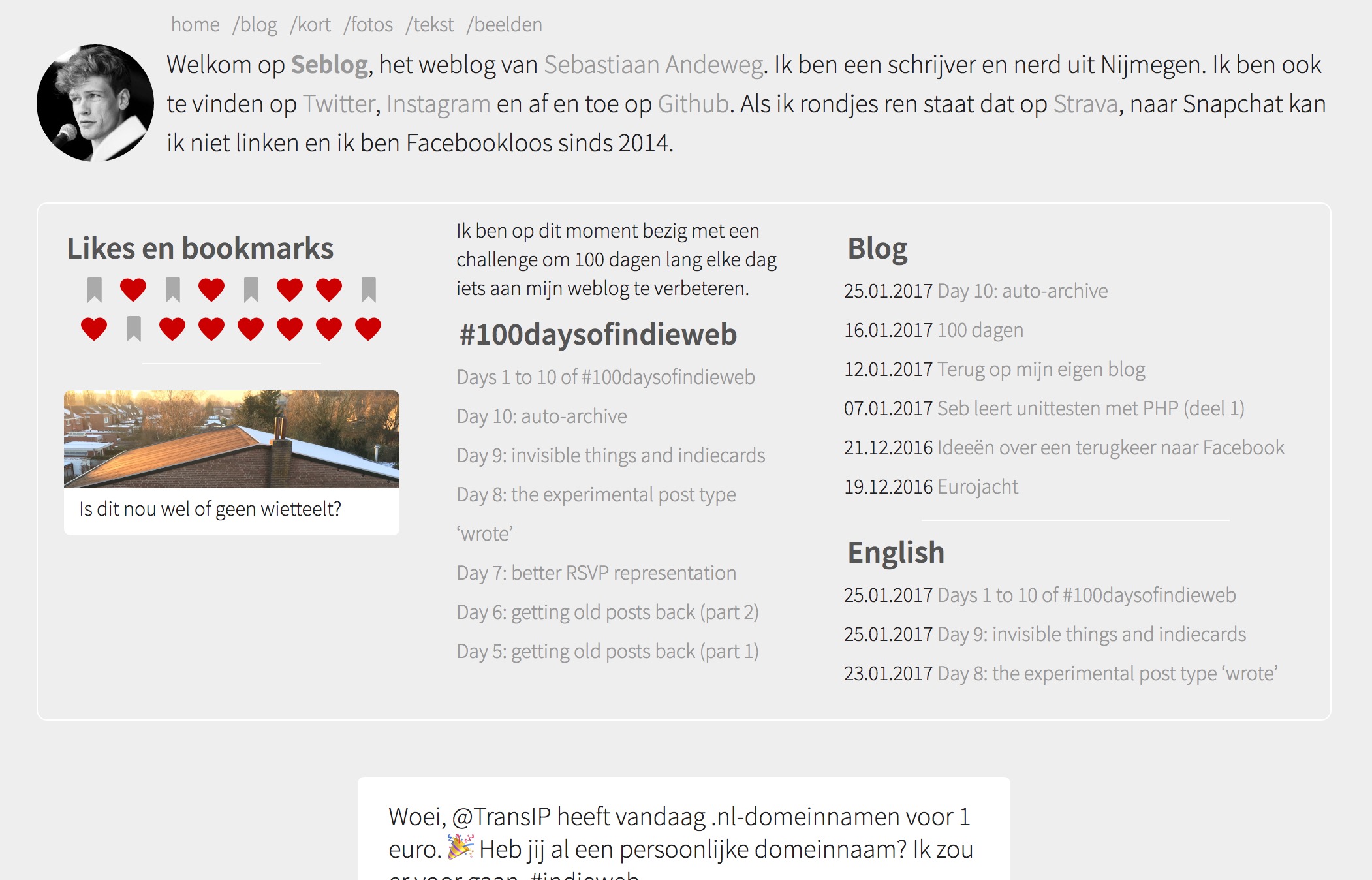
This way I can provide a summary of what’s going on on my site. It gives me a framework, where I can always swap parts. The #100daysofindieweb tag, for example, is now a good thing to have, but is less needed 100 days from now.
 Seb gaat naar . Seb heeft dit gebookmarkt.
Seb gaat naar . Seb heeft dit gebookmarkt.I’ve been doing this #100daysofindieweb thing for 10 days now, so I thought it was time for a summary post. Here are the things I've been working on:
I fixed how things look here on my site quite a lot. On Day 1 I fixed how my reposts look. They are not longer just a url, but now actually show the original post, which I stored during the Twitter dump. I don’t do an automated grab of the external page yet!
I also changed now my RSVPs look on Day 7. First they where just a reply post, with a weird textual representation of ‘yes’ or ‘no’, but now they have icons.
On Day 8 I launched a ‘new post type’. In a way, this is just an different presentation of the posts I write for the purpose of writing them. I now only show the word count on those posts, not the text, because the actual text is less important.
On Day 3, I fixed some bugs regarding relative urls, not only in my own Webmentions plugin, but also in the Kirby Toolkit. It eventually led to a new test on Webmention.rocks.
Today I also added an auto-archive function to my plugin, so it triggers archival copies for any url I mention.
I spend Day 5 and Day 6 importing old posts, which was actually quite hard and is still not really finished. I’m quite picky about how things should look, and they don’t look very good at the moment. There are also a lot of duplicate posts, because I imported my Twitter, and I used to link to my blog on Twitter. I still need to fix these things, but since I already spend two days on this, I postpone it some more.
On Day 2, I marked up my deleted posts. If a post has a dt-deleted in the past, it returns a 410 Gone header on it’s own page, and shows up as a hidden tombstone in the feed.
And on Day 4 I changed the HTTP header of posts with a dt-published in the future to 404 Not found. Together with hiding them from the feed, this makes scheduled posts.
Finally I fiddled a bit with my Microformats on Day 9, so my site comes out better on Indiecards.
All in all it feels like a productive first 10 days! Only 9 of those sets to go :)
Yesterday Tantek encouraged people to trigger an archive in the Internet Archive for every url they mention. It is not that hard to do.
So today I added an auto-archive function to my Kirby webmentions plugin, which you can find here. I’m not aware of anyone using it beside myself, but it is set up more or less so that everyone with a Kirby site can use it. (I am planning some breaking changes though.)
I guess, by posting this to my blog, I trigger an archive to a page describing how to trigger an archive. How meta.
Today I did some invisible things. The first does not count for #100daysofindieweb, because it’s too invisible, but the second is valid, I think.
My blog runs on Kirby, which uses .txt files in a folder structure. In order to show you list posts, my server looks at several .txt files. The more posts I post, the more .txt files my server has to open. It all held up quite a while, but since my Twitter import my site contains 8000 pages.
This was not big of a problem for the main page, because I told Kirby to look at the newest folders first, and stop after 20 posts. (They are sorted by date, after all.) But when you want to view only the blogposts, or only posts with a photo, things became slower, because it had to look further in the past. Not to mention what would happen if you ask for a category that does not exist. With 8000 posts, my server would say no.
So I indexed all my posts with a database, a little while ago, and that seemed fine. The only problem was that the database is a pain to maintain. I did add pages to the database when I posted a post via Micropub, but when I edited pages via FTP, I needed to put ?reindex=1 behind the url to trigger a database update for that page. Sometimes you forget that kind of stuff.
Anyway. Today I made a system where entries are cached. I don’t cache the whole page, I just cache the h-entry, the part in this white block. The page now checks wether a .html version of the entry exists, and also checks the timestamps on the .html, the .txt and the entry.php snippet. If the .html turns out to be current, it shows the .html, and if not, it generates a new .html file and shows that new one.
With this new event, I reindex when the .txt has been updated. I still have to visit the page to trigger a reindex, but it’s much more smooth and almost goes without thinking. I’m very happy with how things turned out.
Unfortunately, all of this is not visible, and I haven’t opensourced this part either. And that’s not how things work in this challenge.
So, I needed to do something more visible for #100daysofindieweb. Yesterday I read about Kevin Marks’s Indiecards, and my site turned out weird on them. The main problem was that Indiecards look for the first h-* element on a page. Before today, the first h-* element on my homepage was a h-feed.
I fixed that today: my homepage now first gives a h-card. My h-entry pages still use that ‘same’ h-card as a p-author. Only my feeds now have a u-author set to /, which translates to https://seblog.nl/, which translates to the h-card on my homepage. More people do this, so I should be fine.
Het ziet er naar uit dat chocochipcookies geen adequate vervanging voor hardlopen zijn. #sugarrushvsrunnershigh #hardloopblessure
Ik keek net A Series of Unfortunate Events S1 E1: The Bad Beginning, Part one.
Yesterday I admitted on IRC that I have quit the #100dagen500woorden part of my challenge. I already stated some doubts but Tantek added me to the wiki anyway.
I felt bad for giving up (so early!) but I felt even worse about posting strange unfinished texts on my site. That’s why I quit: the challenge didn’t feel good.
Today I thought about it some more. I needed a new post-type, where I only post how many words I wrote in a day, not the actual words I wrote.
Compare it with NaNoWriMo, where thousands of people write a novel of 50,000 words in the month of November. The actual text you write in that month does not really matter. The only thing that matters is writing a certain amount of words.
I never participated in NaNoWriMo, so I have no data to export in this format, but I can actually participate this year without having to put my data into NaNoWriMo.org.
Now for the implementation details. I have the following .txt-file on my development server:
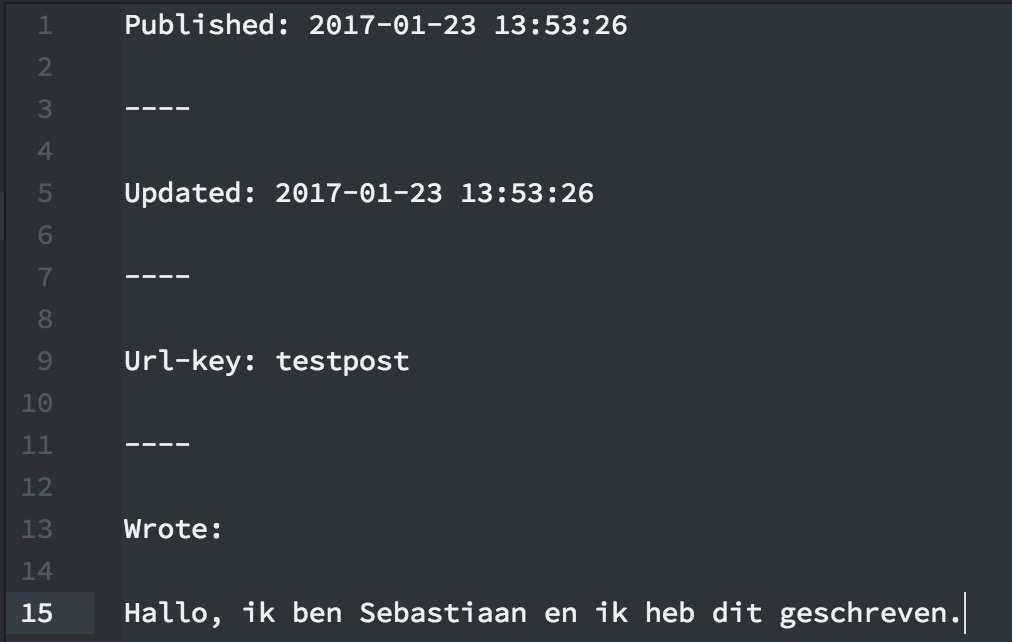
This translates to the following public post on my blog:

As you can see, Seblog calculates the amount of words for me, so the only thing I have to do, is write a text and put it under the wrote field. I mark up the number of words with a p-words class, which is probably not consumed by anyone, but hey, I publish this kind of data now.
Now I have no excuse anymore to pick up some writing again.
Last but not least I want to coin the term ‘iceberg post’. A ‘wrote’ in the way I implemented it is an example of an iceberg post: there is a public part and a non-public part to it. It’s just a case of Partial Page Privacy, but I think the term ‘iceberg post’ has a nice ring to it.
Seb vindt Vladimir en Estragon van Willem Sjoerd van Vliet leuk.A little while ago I posted my first event, and soon after it came my own RSVP to that event. Back then I wrote a bit of text, because an Indieweb RSVP is a h-entry with a u-in-reply-to and a p-rsvp property. Since it’s a reply, I wrote reply text.
Most people don’t display the text for RSVP posts though, myself included. And today I RSVP’ed on a Meetup.com event, so after the ‘hey you need to post this on your own site first’ bells went off I made a new RSVP on my site. I forgot the text, so it looked like this:
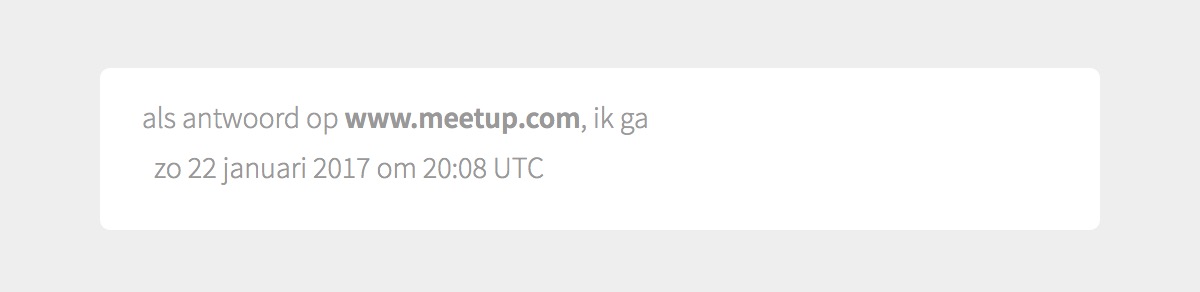
It’s a bit yucky. So since I already have icons here for displaying the different RSVP values (yes, no, maybe and interested), I thought let’s re-use them.
I changed a lot of code behind the scenes too, because my h-entry template became a mess with all the different options it has. (But behind the scenes doesn’t count for #100daysofindieweb!) I now display RSVP’s as what I now call ‘shortposts’:

I also added my bookmarks to the feed at the homepage, because I like to show off my different types of shortposts. (They first where only available at /bookmarks, and I'm actually subscribed to that feed myself, so I can review my own bookmarks in my reader. Nice lifehack.)
Seb gaat naar .I got my posts back! :D
Unfortunately the quality of the dump isn't very good. Markdown is sometimes not interpreted, there are double posts (Tweets linking to my blog or Instagram) and a lot of images are at width:500px, which was my default width for over 10 years.
I've been coding some kind of post-match code, too see if I can detect the double posts. It quite hard, because a lot of tweets that are not the same post, are send within 15 minutes of each other, so published is not a good predictor. Trying to calculate the text similarity with levenshtein() seemed like the solution to all my problems, but there are quite a few mismatches still. I probably can't do this fully automated.
I now really have to go to do some real-life stuff, so I guess today just has to be the day I imported the posts and added the images. It's not that I haven't put in the hours today, it's just that it's way too much. (Or I need to be more efficient) You can check things out by scrolling way down in my feed, or at /blog or /tekstbeelden.
I have good news and bad news. The good news it that I made a lot of progress in retrieving my old blogposts. The bad news is that I don’t think I can finish this today anymore.
tl;dr: I have my posts in Kirby-formatted .txt-files now, but I need more time to think about moving the images.
In an attempt to own my data, I posted all my Tweets and Instagram-photo’s onto my weblog. To do so, I started fresh, but I never got around to post the old posts back. I have 8000 posts on this site, but the old one’s are all social media reposts, no originals, even though I have had this domain since 2006.
There are roughly four periods between 2006 and now. In the first 5 years, I used a custom made CMS, written by a 16-year-old who taught himself PHP by reading a 175 paged book. (That’s me.) In 2009, I found it too insecure to keep it running that way, so I moved to Wordpress. Looking back at it it wasn’t so insecure at all. Yes, I was 16 years old when I wrote it, but I knew about SQL-injection at the time, and Wordpress isn’t known for it’s security. My own blog at least had security by obscurity.
At the beginning of the Wordpress era I made a fresh start. Luckily I found the old server still running, so my posts should still be there in that database. (You can send a GET request with Host: seblog.nl to my mother’s website to get the last pre-Kirby version.) If not, I have a PDF somewhere, but that’s not great for importing.
After a while I moved away from Wordpress in favor of .txt-files. I did a proper import back then, so that’s where I’m working with now: the .txt-version of my blog.
And those files are great, but hideous. Somehow I thought it was a nice idea to link them together with Javascript, so this version of my blog is not archived by the Web Archive. It worked like an infinite scroll: I had one file called ‘blog.txt’, which only contained a link to the last post. At the end of that post was a link to the next post. I think my 404-page showed a C implementation of the linked list, because that was my inspiration.
Next to ‘blog.txt’ I also had ‘verhalen.txt’ and ‘tekstbeelden.txt’ for other streams of posts. In my import I wrote a nice little recursion to get a list of all the stories, so I can tag them properly:
function findnext($from, $links, &$a) {
if($links[$from]) {
$a[] = $links[$from];
findnext($links[$from], $links, $a);
}
}
$verhalen = [];
findnext('verhalen', $links, $verhalen);There is also a lot of Markdown-that-isn’t-Markdown in my posts, which complicates things. Oh, and Wordpress-HTML. I’m trying to regex a lot out of it.
The last problem I have now are images. In Wordpress and my own creation I stored all the images in one folder, but in Kirby the convention is to store them in the folder of the page. (Kirby is one big folder structure. I like that.) I need a way to either upload them when I post the posts via Micropub, or a way to identify the location of the newly created posts from the old slug, so I can move the files on the server. I don’t want to do it by hand.
This blogposts gets hopelessly long. Maybe I could’ve fixed my images-problem by now. But I want a clear head before I start importing. And a backup, but with 8000 posts that takes some time. I’ll resume tomorrow. At least I made progress!
This is a scheduled post. I hope I sleep at this moment.