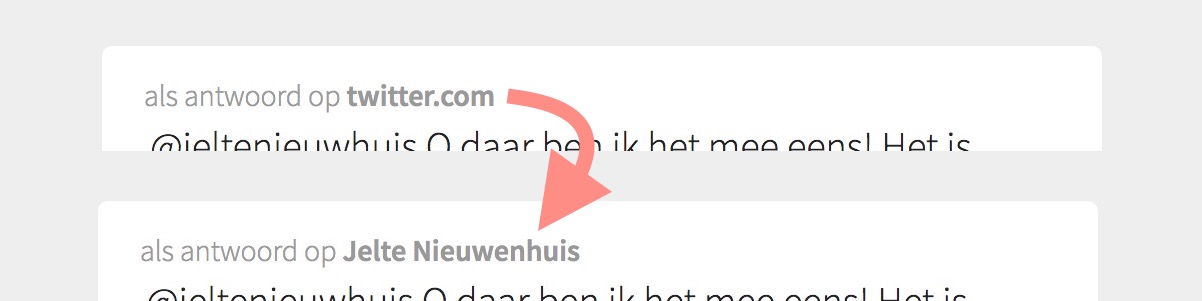
Today, I replied to some people on Twitter, and I was surprised to see 'twitter.com' turn up on my site as the author of the post I was replying to. I now have XRay with Twitter vision, right? Why didn't it work?
It turned out I only use XRay for likes, bookmarks and reposts, but this reply context relied on an old piece of code I wrote myself. It fetches a h-card for the URL, which works for IndieWeb sites with Microformats, but not for Twitter posts.
So I fixed that: now XRay fetches context for replies too:
This is the first step in actually displaying the full reply context on the permalink page. The data is there now!
Today is a (almost) no code day. I wrote a privacy policy.
Now that I have ways to log in to my site, I kind of need a page, because I am handling with personal information. I believe it's even required for the Twitter login thing, so here it is.
It feels more formal than I want it to be, so I tried to keep it informal. I also translated the Dutch version into English, because I have embarked on this multilingual thing now with this 100days series and English visitors need a privacy policy too. The document just comes down to explaining what I do, and asking to contact me if one disagrees. I don't do crazy stuff, so I think it's fine.
The bit of 'code' I wrote is in the footer, where there's now a link to the privacy policy.
At some point while building the foundation for this site, I decided to save all dates in UTC. I like UTC, I like timezones in general, and here in Europe we're not that much off UTC either.
In about a month from now, though, the gab between UTC and CET will grow again with one hour, due to 'zomertijd'. And even though there was an explicit 'UTC' behind all the times, it was still confusing for Dutch visitors, who where expecting 'normal' times.
I now show times in Central European Time. There's an explicit 'CET' behind all the times. The Microformats times are still on UTC though, but I added an explicit +0000 behind all the timestamps, to make clear that it's UTC.
One of the things I keep changing my mind about, is reposts. They are totally normal on Twitter, but seem to be totally weird on your own site. When signing up for Twitter, you give permission to Twitter to let other people retweet your tweets. When signing up for IndieWeb, yeah, non of that exists.
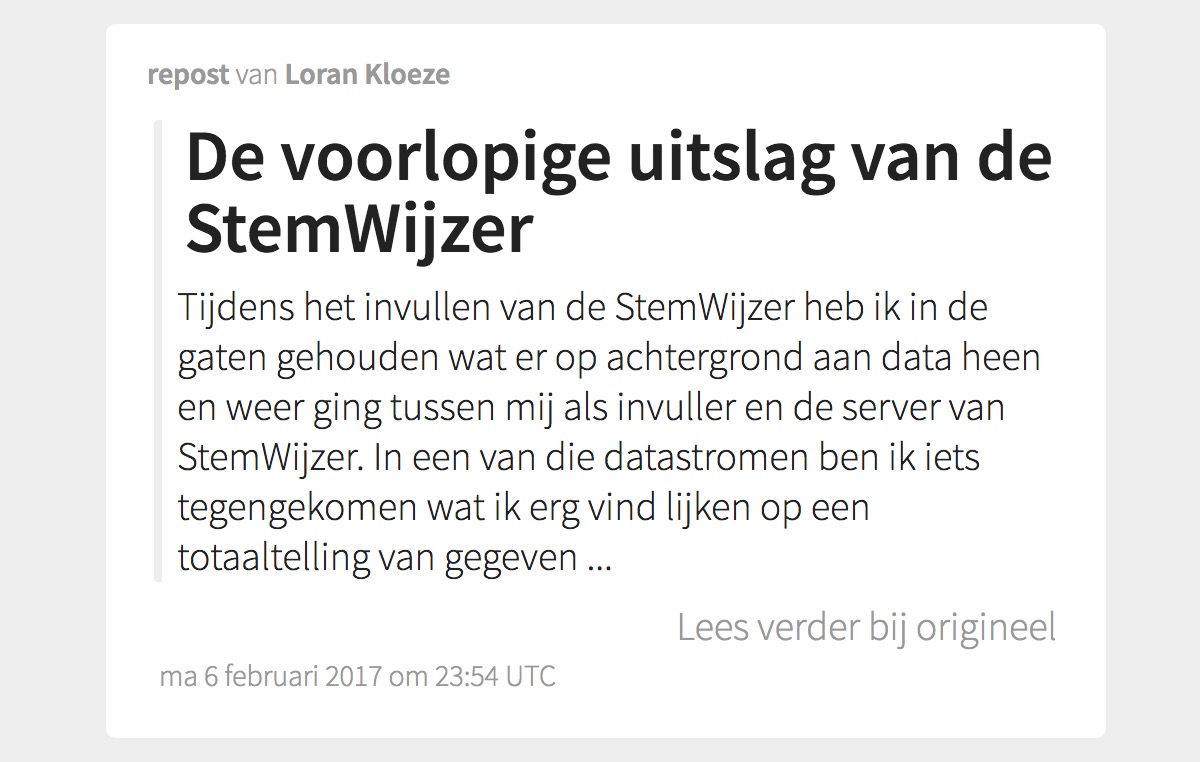
Still, I reposted a post by Loran Kloeze two weeks ago. It was marked up with h-entry, so all I had to do was just feed my Micropub endpoint the URL, and my site automatically fetched the post for me. At that time, I thought it was good to do so, because the post was important and chances were Lorans server would not have handled it if it went viral. I mirrored it, so others would be able to mirror it. Sounds good, right?
I still did not ask permission for the repost to Loran. (And I doubt he knows about it... maybe he gets a Google Alert after a while? He does not support webmention.) Yet the whole post was available at my site. What about those copyrights? He has removed his Google Ads now, but at that time they where there, and I was potentially keeping visitors away by giving them an ad-free environment to read the post.
So, today I changed some things about how I repost. I only show the first 50 words in the stream, like this:
There is a link to read more at the original URL. Tweets are, with 140 chars, mostly kept as is. I am just quoting, but the whole post is so short that I display all of it. The longer posts are cut off, to encourage people to read it at the source. If the permalink expires at some point, I can always decide to show the whole post again. Or maybe I should delete the repost then? That depends on the post.
When visiting a permalink of a repost on my site, you will get redirected to the original post. This way, reposts only appear on my stream, and I don't host their content under a URL on my site.
Okay, I did not implement receiving private webmentions today. Reason for that is that I also need to do some other things in life, but on top of that: I don't like the way I am storing webmentions right now. I feel like I have to solve some other things about that, before I can actually implement receiving private webmentions. I could just go for it, but then I am just adding more on top of this thing I don't like, which makes it harder to change, etc. I will make receiving private mentions a gradual thing, spread out over more days.
I still need to do something today, but it was hard to come up with anything, for everything seems to big for the time of the evening. So I decided on something minor: I now randomise the post that are visible in the 'Read' view of Lees. Wait, let me first introduce you to that.
Lees, the Dutch word for 'read', is my IndieWeb reader. It is all quite experimental and unstable, so I don't recommend using it, although the code is open. (Do I have a good license there? No. I need to look into that.)
Lees just polls different websites via a cron job and pulls Microformats from the posts. It presents those posts in a 'new' feed, 10 at a time, oldest first, so you don't miss a thing. Then there is a button that says 'mark all as read', which marks all the posts in the current view as read. This is great for reading tweets in bulk.
Some posts need more time, though, so there is a 'read later' checkbox. Checking it will, after you click 'mark all as read', not mark the post as read, but send it to 'read later'. This way you are just glancing at the 'new' feed, and picking the things you really want to read.
As you can see above, you can also like, reply and bookmark directly from Lees. Well, reply is actually just a link to Quill, but it's still works. There is build-in Micropub support for the on-click-post ones.
My problem is that Lees does not yet filter stuff. I follow too much people on Twitter, so now I actually removed Twitter from Lees and check the Twitter-app again. I also have a list of articles I would like to read in my 'Read' stream, but I see only the same ones over and over again, the oldest 10. Every time I see them, I think 'yeah, I should read those', and that guild does not really convince me to do so.
So in an attempt to get myself back to Lees, I randomised the posts in the Read section. Their order is now shuffled, so I see 'new' ones when I login. Those are all posts I handpicked for looking interesting. I hope I am now more motivated to actually click some of them, as I rediscover them. Also: if I now keep seeing a particular article that I don't read... I can remove it with more confidence.
So there it is, day 31. Writing this blogpost took longer than the thing, but I'm happy with the result, that's what counts!
Now that I support both private posts and webmention, it is time to put those two together and send private webmentions. In short, this is a way to notify URLs you mention in your posts, while still maintaining the privacy of the post.
Following the description on Indieweb.org, my private posts now send a HTTP Link header to my new token endpoint. When I send a private mention, I also send a code: a JWT token with the target and source URLs of the webmention and an expiration of 2 minutes. The other side can discover my token endpoint by looking at the Link header, and send the code in a POST request.
The code is then exchanged for an access token, but now with a me, which is set to the URL of the mentioned post, a page, which is my page, and a nonce to mess things up a little. This access token expires in an hour, which is plenty for automated fetching, but might be a bit short for people verifying manual. Normal people can still try and login via IndieAuth though!
However, the mentioned URLs and the whitelisted people are different fields, so they can be different. In fact, they should different: if I mention someone.com/a-post, I might to give someone.com access to the post by logging in, but only if the owner of someone.com/a-post is actually someone.com. In case of twitter.com/url-to-tweet, I don’t want to give twitter.com access. I’m not sure how to solve this yet, so I will do it manual until it hurts.
Also note that I only implemented sending private webmentions today. Please don’t private-mention me now. I will do that part tomorrow.
Now for the Special Valentines Edition™: I just created a post with a u-like-of pointing to a personal site / profile of someone I like. The post is of course private and only I and that person can see it when we log in. I have sent a private webmention for it. The only sad thing is that the other side did not support private webmention and nothing got sent, so I guess it does not really count as my first private mention. Tragic Valentines Day for me so far.
Yesterday, I found a weakness in Quill, so I notified Aaron and he fixed it today. (Actually, I discovered it today at 1:30, and he fixed it yesterday at 20:30. Timezones are magic!)
On Day 15 of my 100days, I found a vulnerability on my own site. I promised to blog about it, but I actually waited, to give Bastian Allgeier the opportunity to fix his site too. Then I just postponed the writing some more, because life happens. I finally wrote about it today.
This brings my count of responsible disclosures to 2, and I’m a bit proud of that.
Two weeks ago I wrote that I hacked my own site. I think it’s important to share how I did it, to make people more aware of possible vulnerabilities, so they can find them too. If others didn’t write about their findings, I wouldn’t have found this one.
I did my best to reach out to people using the same code. If you are using the Kirby Webmentions plugin or my fork of it, please make sure to update!
Webmentions
As some of you may know, my site supports webmentions. In short, this enables me to show replies underneath my posts, that are written by people on their own site. If you write a reply, link to me, mark it up with Microformats and send a webmention, my site fetches your post and shows it as a reply. I use a service called Bridgy to also receive comments from Twitter and Instagram. All of this is automated and very cool.
However, while very cool, it is also potentially dangerous to show external content on your site. The vulnerability I found is an example of what can go wrong.
If you look around on my site, you see I do not only show the content of the reply, but also a picture of the author, if provided. This is especially nice when showing likes:
In order to protect visitors of my site from other security issues, the plugin downloads the images and shows those downloaded ones. This way my visitors only deal with my server, and not with the servers of everyone who liked my post. It’s a nice service, but it also means that I move the problem: I now have to handle those images with care on my side. My server takes the fall for my visitors.
The problem is: my server just downloads whatever image you give it. In most cases, this will be a nice avatar I can display for my friendly visitors. But one can think of a case where a not-so-friendly visitor feeds my site something else than an image. The plugin of course checks if it’s an image and rejects files that are not a image, but it’s still worth a try.
So, what did you feed it?
Since my server runs on PHP, the nicest thing for an attacker to feed my server is a PHP-file. That way, you can run whatever code you want on my server, doing all kinds of evil things. However, just straight off feeding my site a PHP-file did not work. The plugin is not crazy. It checked wether the MIME of the file was an image of type jpeg, png or gif. It rejected an image.php file like this:
echo "hi!";
Using image.jpg as filename would fail too: the plugin saw that the file had no MIME of an image, so it did not download it. This was the point where I went to bed with a feeling of security: my site was safe and I could not get a php-script in.
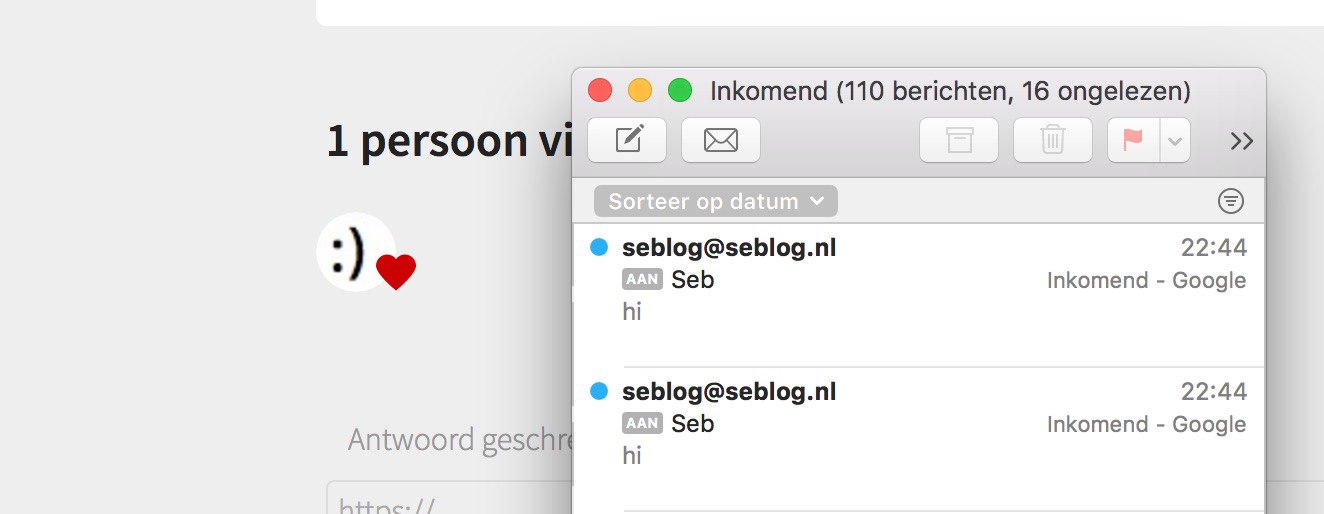
The next day, however, I had second thoughts. I needed a real image for my new plan, so I took a screenshot of a smiley. I then opened it in notepad and added the following to the bottom of the file:
<?php mail(‘my.email@gmail.com’, ‘Seb’, ‘hi’);
I then renamed the file to image.php, because you need the PHP-extension in your file to let the server run your code. The last step was disabling PHP on my test-server, to prevent the test-server from executing the code and send mail me. The code just appeared at the end of the image.
I then made a test-post with a u-like-of set to the URL of a post on my blog, and a p-author h-card with an <img src="/photo.php">. It was a like, with an author and an my bad image.
And it worked.
The server sees the image and checks for the MIME, which was image/jpeg, because it was an image. It then downloaded it, including the un-executed PHP string in the bottom of it. It changed the name of the image into the SHA1-hash of the original image-url, but then it appended the extension of the original file, which was .php!
My server then had a file called a266d629bb26d74752080bb1b95bbd0a488bea53.php, which was linked as an image in my post. Every time I refreshed the page, the snippet of code in the bottom of the file got executed, so it sent an e-mail to me.
In this example, I sent an e-mail, but it could’ve been anything.
How to solve?
First off: check your input! And then check it again. A crucial thing for PHP-files is that they get executed if they have the .php extension, so you should not rely on user input for that. Change the filename and change the extension.
Bastian updated the plugin, so now it does not only check for MIME, but also only accepts files with the extensions jpg, jpeg, png and gif. Only if it has a correct extension, it downloads the file, and it checks MIME twice, both before and after the download. I think it’s locked down pretty well, although it still feels a bit scary.
Aaron Parecki, who did this way of showing likes first, uses an external service for his webmention images, and that’s not a bad idea either. If someone manages to get in something bad, it’s not on your the same server as your site. It could also be a good idea to turn off PHP for your upload folder, if you have that kind of access to your server.
Final words
I really like this webmention plugin! It’s thanks to this plugin that I know IndieWeb and all the wonderful things it brings.
But while the plugin and IndieWeb are nice, it’s also good to keep and eye on security. At this moment, webmention is relatively safe because not many people know about it or use it. Although it can be a lot of fun to have a post of a friend automatically show up beneath your post, we have to be aware of the risks of showing content of external parties.
Taking yesterdays private post adventure one step further: it’s now also possible to log in to Seblog with Twitter. I still recommend having your own site and use IndieAuth, but I have to be pragmatic: a lot of my friends do not have their own site. (If you want your own site, like this, just give a shout, I can help.)
To make this login adventure a bit more visible, I also added a ‘Log in’ link in the top right corner of every page.
Unfortunately, there is not much going on for people who logged in via Twitter. The private post of yesterday is still only visible for those who were on IRC-people yesterday. But it’s a step!
A few months ago I wrote that I made 'privéstukjes' on my site. The implementation was as simple as one field called 'private' that I would give a value (true for example). If the field has a value, my site returns a 401 Unauthorized header and a page explaining that there is nothing to find there. I did not implement a way to log in, for I only used it for (two) drafts / pieces of bad writing I wanted to keep for myself.
But what is the fun of a private post when nobody can see it?
Today, I implemented a login for my private posts. It was a bit more work than I thought, getting IndieAuth to work and thinking out all the different states of a post, but I made it.
Posts can now also have an 'audience' field, where I keep a comma separated list of URLs that have access to the post. I plan on expanding or replacing that with predefined lists (friends, family, etc.), but for now this works fine.
If one is not logged in, the private post page returns a 401 with a (Dutch) explanation of what is going on. There is also a field to put in your personal URL for an IndieAuth login. If you login, but are not on whitelisted to view the post, you will get a 403 Forbidden, and a Dutch explanation. (Translating my site based on visitor language is still a to do.) If you are on the list, you will see the post.
I have made a test post, so you can try out for yourself. All URLs on IndieWeb's IRC-people page, at the time of writing this, are whitelisted. Have a try at it if you're on that list!
Oh no! I almost forgot to work on something IndieWeb today. This was partially the plan, because I also want to focus on some writing (which did not really worked out), but I still wanted to do something small in the evening to keep this thing going. And that part I almost forgot.
So here is a really small change: Tantek was talking about reply contexts for RSVPs, and I said I only show the name of the event, and asked if that counts. And yeah, in a way it counts.
I wanted to add a bit more though, so now I also show the date of the event:
A very minor thing, but hey, it's a thing! I don't really want to add more details to my RSVPs, because I like them small and people are one click away of knowing more about the event anyway.
A blast from the past: I have an RSS feed and it's available at seblog.nl/feed.rss. (I also have seblog.nl/feed, which is actually the h-feed version of it.) I made the RSS feed a while ago for Martijn, who I believe is my only subscriber at the moment.
Back when I made the feed, I didn't want to put in much work for it, because I already have a couple of rich h-feeds. So I made it so that "if a post has a title, give that, else, just call it 'post'" and "if a post has content, give that, else, just say 'A post on Seblog'". Very lazy. It turns out I actually have a lot of posts that have neither a title nor content. Things like my likes, reads and bookmarks all have no title nor content, because it is stored in different fields. So my RSS feed ends up being filled with contentless posts.
I am still lazy about my RSS feed, but I improved it a bit. I now just call the same snippet that produces the HTML for the frontpage for the content of the feed item. This means the whole post is in the RSS feed. Probably not the best way to do it, but hey, who uses RSS nowadays anyway?
Today I was at Homebrew Website Club in Utrecht. We had some talks, showed some stuff, and then coded for a while. (You might say that we switched the quiet writing hour and the talks around, but we were not silent all the time.) Jesse made a first version of a blog section on his site and Martijn did some tweaking on his habit tracker.
I made it easy for myself: I just copy+pasted my existing [media endpoint](https://www.w3.org/TR/micropub/#media-endpoint) into my Indieweb Toolkit. Then I spent the rest of the time tweaking, cleaning and improving my code. The whole endpoint is now contained in a single static method, which takes a string with the path to the upload folder, and a string with the public URL of that same folder. It validates access tokens, saves media with a sanitised filename and an unguessable prefix, like vx5dgk-image.jpg, and then returns the URL of the uploaded file in a Location header.
Okay, I admit: I already did this yesterday, as you can see from my previous retweet. But I wanted one day off. One day without screens. So that’s today.
Earlier on I made my site like tweets when I post a like to a tweet on my site. This means I get just feed my Micropub endpoint an URL as a like-of, and don’t think about it anymore. Now I added reposts to this too, so I can just paste a link in Quill and it’s ok.
I also seemed to miss pictures in reposts since I redid them, so I fixed that as well. It’s the little things. See you tomorrow!
In December I already posted some plain text notes tracking my reading progress in Stoner by John Williams. (The Dutch translation, by the way, because I got that one somewhere in a very portable version and I was on a city trip to Vilnius.) I already planned to upgrade those plain text notes to a more standarized format, so that I would have /read posts.
Before I could add them, though, I needed a way to give them URLs. So now I have this public list of books I own / owned / want to track, on my new library page: /bieb. All books in there are marked up as h-cites and have a url in the format https://seblog.nl/isbn/9780123456789. Their u-uid is set to isbn:9780123456789, because that seems to be a valid url scheme (but browsers don't know what to do with it).
The next step was simple: I just expanded my shortpost type with a 'read' type, that looks for a read-of field. Thanks to XRay and my existing code, the seblog.nl/isbn/-url gets expanded to a title and author. I also added a page field, because I posted when I was at certain points at the book, and I actually haven't finished it yet.
Today I added a very basic Micropub endpoint to my Indieweb Toolkit. A Micropub endpoint is a hard thing to keep generic, because every site has a different way of storing data. The idea about the endpoint in the toolkit is that it does all the things that are the same about Micropub.
So here's an example of what it can do. This one simply writes a YAML file with the received fields to a folder. Please note that it overwrites any post with an existing slug. It's only an example.
The idea is that you can put this code where-ever you want. It can be at /micropub.php or in some route you define. The new endpoint::micropub() does all the authentication for you and returns the appropriate header. All you need to do is pass in a 'create' callback function, which takes the fields and returns a URL. endpoint::micropub() will do the redirect with a 201 header.
At this moment it only supports 'create' with x-www-form-urlencoded, but JSON and 'delete', 'undelete' and 'update' will follow. I also want callbacks for different mp-synticate-tos, and of course there is the ?q=config query. But I like this idea, and will use this idea to clean out the code of my own endpoint.
Last caveat: at this moment I have not implemented the IndieAuth class in my toolkit. You can steal the class from my kirby-micropub plugin, but I want to clean it first before putting it in the toolkit.
Today I drafted a SiloAPI class in indieweb-toolkit. The idea is that it gives an easy way to interact with different Silo API's. In some ways this is a bad idea, because all API's work different and have different capabilities, but I like the idea, even if it's bad.
One API call that is available for both Twitter, Instagram and Facebook is to create a like. So that's where I focussed on first. Today, I made SiloAPI a wrapper for the TwitterOAuth PHP library, and it now supports ::like() just like micropub::like(). You still need to pass in the name of the silo though, but maybe I'll detecting the silo from the URL later.
Then I realised that Brid.gy probably can do this for me too, since it already syndicates my Tweets for me when I ask for it. So I just made my Micropub endpoint call Brid.gy publish for every like-of that is a twitter-URL.
I will add to SiloAPI though, because I want to autolike to Instagram too!
Today is a weird day. Fixed a lot of things, but also did kinda useless things. (I learned more about HTTP requests by trying to create a Micropub request using netcat, and at some point, I was chatting with myself in two Terminal windows with nc -l localhost 8080 in one and nc localhost 8080 in the other, completely by accident.)
Then it was 1:30 at night.
Earlier on in this series, I fixed my repost context. These contexts where based on a .json file I exported with my whole Twitter archive. A few days ago I made XRay look up likes for me. Today, I retweeted someone, and since .json files don't magically appear on your server (luckily), it didn't show any repost context.
So I combined the two and now XRay fetches the repost context for me. I don't use the .json file anymore, but keep the data the same way I keep likes: in a refs field.
Today I extended my new Indieweb Toolkit with a Micropub helper class. This allows you to easily send Micropub requests from your PHP code. Here’s an example:
// Set URL and access token of the endpoint to use
micropub::setEndpoint('http://yoursite.com/micropub', 'xxx');
micropub::reply('http://example.com/a-nice-post', "Oh what a post!");
micropub::like('http://example.com/another-post');
micropub::rsvp('http://example.com/an-event', 'maybe');
$newURL = micropub::post([
'name' => 'Custom posts are possible!',
'content' => 'This is a story about (...)',
'category' => ['story', 'custom'],
'mp-slug' => 'custom-posts-are-possible',
'mp-syndicate-to' => 'https://twitter.com/example',
]);
go($newURL);
Note that this only creates posts, and relies havily on the server you are making requests to. The mp-syndicate-to in the above example indicates that the remote server needs to post the entry to Twitter also, this helper doesn’t do a thing for that.
A drop-in Micropub endpoint is hard, because every site stores it’s data different, but I intend to extend this toolkit so that the different parts involved will be easier. (De facto making my own code more re-usable.)
It’s only Day 17, and while there is allways stuff to do, I feel like I got to a point where everything more or less works like I think it should. To put it in another way: most of my itches have been rubbed.
At the same time, I feel like I have implemented a lot of stuff others have already build in some other form. Apart from my questionable new post type, I have not really build new things. And that’s no problem: nothing is entirely new, all things build on top of other things. My problem with it is that I keep building things other people build before me because they build it. I need to step back and think again: do I need this?
Another problem with the challenge is that I did a lot of ‘small’ things already, but keep seeing only big things on my list. This is both a problem (I keep postponing the big things) and the solution (this challenge forces me to break things down!).
There are a few general areas where I want to make progress that are just a bit to big:
Webmentions – I have them working, but I made some changes to the original Kirby plugin that might not be for everyone. I kind of want to start a new basic plugin, providing just sending and receiving Webmentions, possibly including a Panel Widget too (although I don’t use the panel myself). And then offer an extension to that plugin with Microformats parsing and display of comments.
Micropub – I wrote a Micropub plugin for Kirby, and it’s only the best out there because it’s the only one out there. I branched off the main branch to do some guild free drafting of the [update](https://www.w3.org/TR/micropub/#h-update) function. My own site uses the latest commit of that branch, the code is horrible and I have never merged it. The problem here is that there is quite a bit of technical debt in that plugin. It needs fixing anyway, although it does work for my site.
Importing old data – I’m just postponing on this one because it’s not very spectacular. But I think it’s okay to import some stuff every now and then and call it a day. I still have Strava, Hyves, my old Facebook, old blogposts from before april 2009 and three Vines. The problem here is that my current data is not really clean. I have tweets and blogposts that could be deduped, and the utf-8 conversion for some posts seems to be weird. Cleaning data doesn’t sound like a good thing within this challenge, so I’m postponing importing all together.
Private posts – This one might not be as big as the others in terms of work, but is does come in steps. I want to use IndieAuth, but also give Silo-friends a way of seeing posts, via Twitter OAuth and the like. Oh and I might want to write my own Authorization / Token Endpoint for Micropub, but that’s whole other point.
Multilingual / multi topic – This was an itch for me, but this is one of the things I’ve pretty much fixed for the moment. I have multiple feeds of posts, tags, and thanks to indexing it goes fast as well. I might open different blogs on different domains, at some point, and use them like I use Twitter now: post on Seblog and push the post to those blogs. But that’s not a real itch for the moment. It can wait.
All in all there is enough to do, but none of the above things fit in a ‘today I fixed my X’. I need to start doing ‘today I fixed Y of my X’.
As a start of these things, I made a first version for an Indieweb Toolkit. It’s inspired by and makes use of the Kirby Toolkit. I want to put some basic Indieweb stuff in this thing, so I can re-use it for different projects. At this moment it only consists of a Webmention Endpoint discovery function and a wrapper for the php-mf2 Microformats Parser, but more to come!
With the recent events in the USA, I’ve decided that I want to move away from having data on American servers as much as possible. The first thing I want to tackle in that area is my e-mail. Although I do have an address at seblog.nl, I still just redirect it to Gmail.
My computer is currently in the process of backing up my main Gmail. I documented how I do it on the Indieweb Wiki:
Gmvault seems to be very simple and straight forward. It's on the command line, so it's scary for some users, but it does a good job of describing what it does. I did the following on my Mac, and since I can't remember installing pip, I think this works out of the box:
sudo pip install --upgrade pip
sudo pip install gmvault
gmvault sync example@gmail.com
Gmvault prompts for OAuth, with a description. Press enter to open the browser, and you have to make sure you are logged in at that browser to the Gmail account.
Do the OAuth in de browser and copy the key. Paste it in the Terminal
Gmvault does things! I got 6351 mails out of an old account in 16m 14s. It creates a folder called 'gmvault-db' in your home folder, with (in /db/) folders for every month. In those folders are, per e-mail, an '[id].meta' and an '[id].eml.gz'. The .meta is a JSON with info from Gmail (labels/tags, subject) and the .eml.gz is a gzipped .eml, which is just the plain-text e-mail with all the headers.
Having the data is just one step. I will need to think about how I want to manage my e-mail in the future. For now I’m on Gmail still, but I am making plans.
To make today a bit more IndieWeb-relevant (e-mail is not web), I backed Micro.blog, because today is the last day of their Kickstarter campaign.
Although I really like that the project gives Indieweb a lot of attention, it felt wrong to only give to Micro.blog. So I also backed Aaron Parecki with the same amount, for his ongoing 100daysofindieweb. I use a lot of things he made or did first.

 Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
Facebook