Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
FacebookDay 17: okay, what now?
It’s only Day 17, and while there is allways stuff to do, I feel like I got to a point where everything more or less works like I think it should. To put it in another way: most of my itches have been rubbed.
At the same time, I feel like I have implemented a lot of stuff others have already build in some other form. Apart from my questionable new post type, I have not really build new things. And that’s no problem: nothing is entirely new, all things build on top of other things. My problem with it is that I keep building things other people build before me because they build it. I need to step back and think again: do I need this?
Another problem with the challenge is that I did a lot of ‘small’ things already, but keep seeing only big things on my list. This is both a problem (I keep postponing the big things) and the solution (this challenge forces me to break things down!).
There are a few general areas where I want to make progress that are just a bit to big:
-
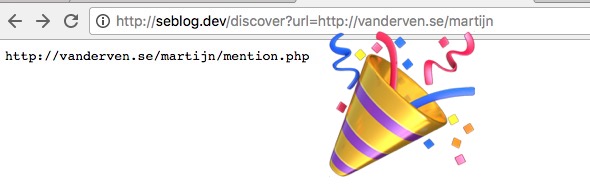
Webmentions – I have them working, but I made some changes to the original Kirby plugin that might not be for everyone. I kind of want to start a new basic plugin, providing just sending and receiving Webmentions, possibly including a Panel Widget too (although I don’t use the panel myself). And then offer an extension to that plugin with Microformats parsing and display of comments.
-
Micropub – I wrote a Micropub plugin for Kirby, and it’s only the best out there because it’s the only one out there. I branched off the main branch to do some guild free drafting of the [update](https://www.w3.org/TR/micropub/#h-update) function. My own site uses the latest commit of that branch, the code is horrible and I have never merged it. The problem here is that there is quite a bit of technical debt in that plugin. It needs fixing anyway, although it does work for my site.
-
Importing old data – I’m just postponing on this one because it’s not very spectacular. But I think it’s okay to import some stuff every now and then and call it a day. I still have Strava, Hyves, my old Facebook, old blogposts from before april 2009 and three Vines. The problem here is that my current data is not really clean. I have tweets and blogposts that could be deduped, and the utf-8 conversion for some posts seems to be weird. Cleaning data doesn’t sound like a good thing within this challenge, so I’m postponing importing all together.
-
Private posts – This one might not be as big as the others in terms of work, but is does come in steps. I want to use IndieAuth, but also give Silo-friends a way of seeing posts, via Twitter OAuth and the like. Oh and I might want to write my own Authorization / Token Endpoint for Micropub, but that’s whole other point.
- Multilingual / multi topic – This was an itch for me, but this is one of the things I’ve pretty much fixed for the moment. I have multiple feeds of posts, tags, and thanks to indexing it goes fast as well. I might open different blogs on different domains, at some point, and use them like I use Twitter now: post on Seblog and push the post to those blogs. But that’s not a real itch for the moment. It can wait.
All in all there is enough to do, but none of the above things fit in a ‘today I fixed my X’. I need to start doing ‘today I fixed Y of my X’.
As a start of these things, I made a first version for an Indieweb Toolkit. It’s inspired by and makes use of the Kirby Toolkit. I want to put some basic Indieweb stuff in this thing, so I can re-use it for different projects. At this moment it only consists of a Webmention Endpoint discovery function and a wrapper for the php-mf2 Microformats Parser, but more to come!