Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
FacebookOn the topic of scoring in NES Tetris, PAL vs. NTSC
tl;dr: This is nerding out on Tetris scores, and quite frankly, I don't think the conclusion holds. But there are nice tables along the way.
I've been watching Classic Tetris for a few months now, and as a result, I'm also playing it. I am noticeably better after I watched some pro's scoring Tetris after Tetris at level 19, so I keep this pace of watching, playing, watching playing.
There is a problem though: at first I deemed playing at level 18 myself impossible, it's just too fast. Then I noticed how my mind could keep up with the players on the screen, but not with the pieces falling on my screen. Of course, I need more practice, but I have an excuse: I live in Europe.
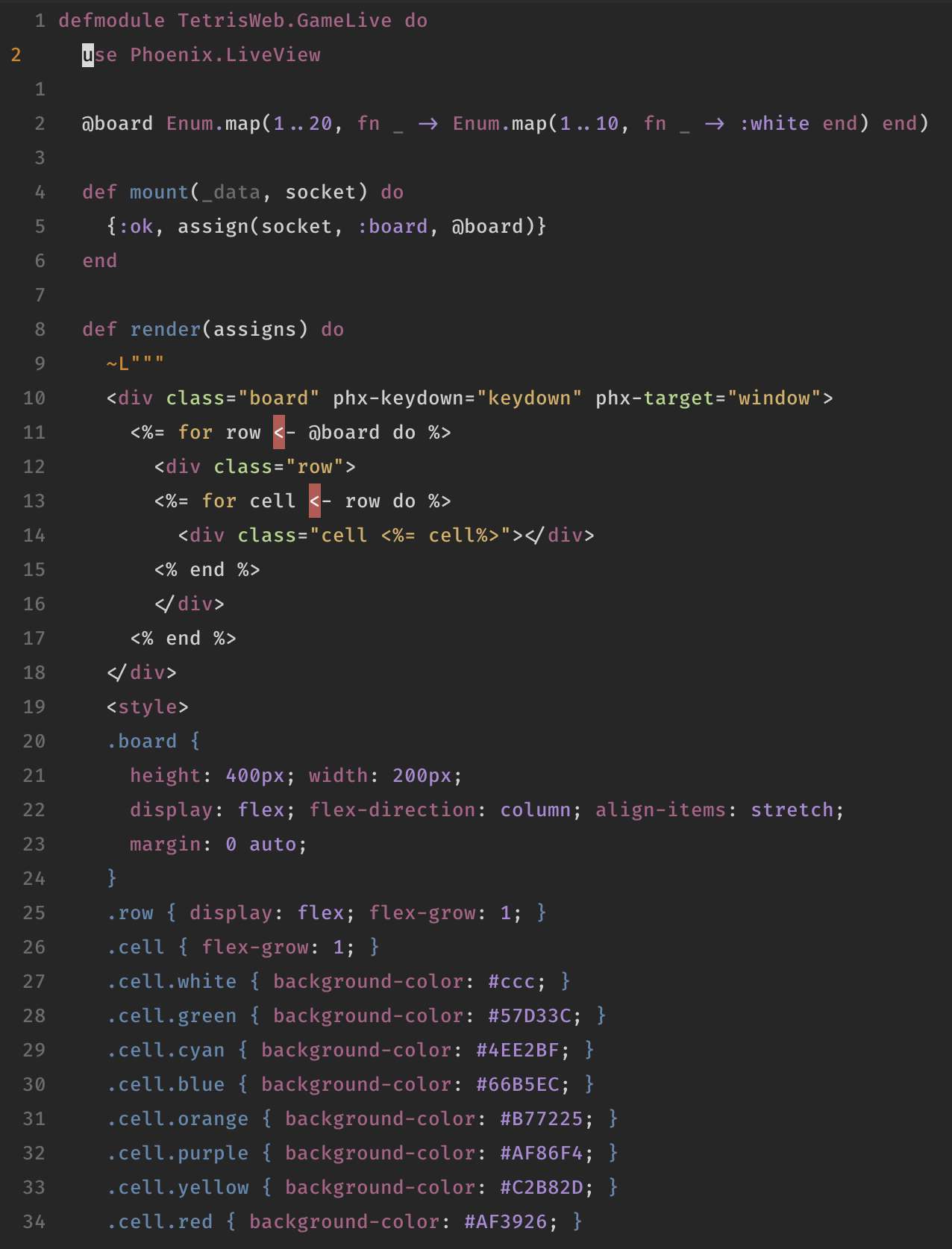
Turns out old European TVs have a different refresh-rate than Americans. Therefore Tetris on the European PAL systems gets faster in earlier levels than the American NTSC systems. There is a nice article by Tetris Finland about this and other differences between the two versions.
Despite the faster speeds of the PAL version, I found no evidence of the scoring system being different. This means the PAL version is just harder, you just get less points for your hard work. (Yea, I will come back at this.)
I am playing Tetris on a real NES, brought ±15 years ago on a flee market at the local community playground for the insane price of 10 euros. The cartridge of Tetris has cost me more. But to compare myself with the pro's on screen I would have to spend a bit more to import an American NES.
Isn't there a way to calculate the NTSC score based on a PAL score?
Yea, is there a way to calculate NTSC score?
My current, not too impressive high-score on PAL is 174_731 (and yes I will use underscores here). How much is that worth on NTSC?
My first attempt was to look at the maximum scores. Players have been known to 'max out' the game on NTSC. A max out score is a score that is higher than 999_999, at which point the score will freeze on those six nines.
On the PAL version, however, we still have a world record, which is currently set to 758_360 by Joseph Saelee. This video is also a demonstration of how much harder the PAL game gets. (Although Joseph has a talent of making Tetris look easy on all versions.)
With some tweaks in the software you can get Tetris to report past 999_999, so higher scores are known. But for simplicity, let's take the world record and equate it with a NTSC max out score. This gives us ntsc = pal / 758_360 * 999_999, which will give me a NTSC score of 230_406.
But is that accurate?
It's always comparing apples with oranges, but I feel like this formula is a bit too loose. Let's bring in the information of the aforementioned article of Tetris Finland, which gives a nice table that compares the different frame rates, and calculates per level the time it takes, in seconds, to drop 20 spaces. Here is a table with that data:
| Level | NTSC | PAL |
|---|---|---|
| 9 | 1.996 sec | 1.999 sec |
| 10-12 | 1.663 sec | 1.599 sec |
| 13-15 | 1.331 sec | 1.199 sec |
| 16-18 | 0.998 sec | 0.7998 sec |
| 19-28 | 0.6655 sec | 0.39994 sec |
| 29+ | 0.33278 sec | as above |
Now, the scoring stays the same in both versions, but changes per level. Let's bring that down to a single number per level, let's agree on a perfect score.
The best way of scoring points is to only score tetrises (clear 4 lines at once). Each tetromino is made up of 4 blocks, and the board is 10 blocks wide. A perfect score would be if the Random Number Generator (RNG) gives us only lines and we can stand them up over the full width of the board, resulting in a tetris and an all-clear board each 10 pieces. This is not really achievable, but this would be the best score possible.
According to the Tetris Wiki we get 1200 * (level + 1) for each tetris, and scores are calculated based on the level after the line clear. Let's ignore push-down points. Let's also say that if the drop speed goes below 0.5 sec for 20 spaces the game is over (this makes levels 29 for NTSC and 19 for PAL the kill screens).
Then there is the concept op the start level. When you start at level 1, you go up to level 2 after 10 lines. But when you start at level 18, you get 130 lines before going to level 19, after which you get a new level ever 10 lines again. The Tetris Wiki gives the formula of "(startLevel × 10 + 10) or max(100, (startLevel × 10 - 50)) lines, whatever comes first". This means 100 lines for levels 9-15, then 110, 120 and 130 for 16, 17 and 18.
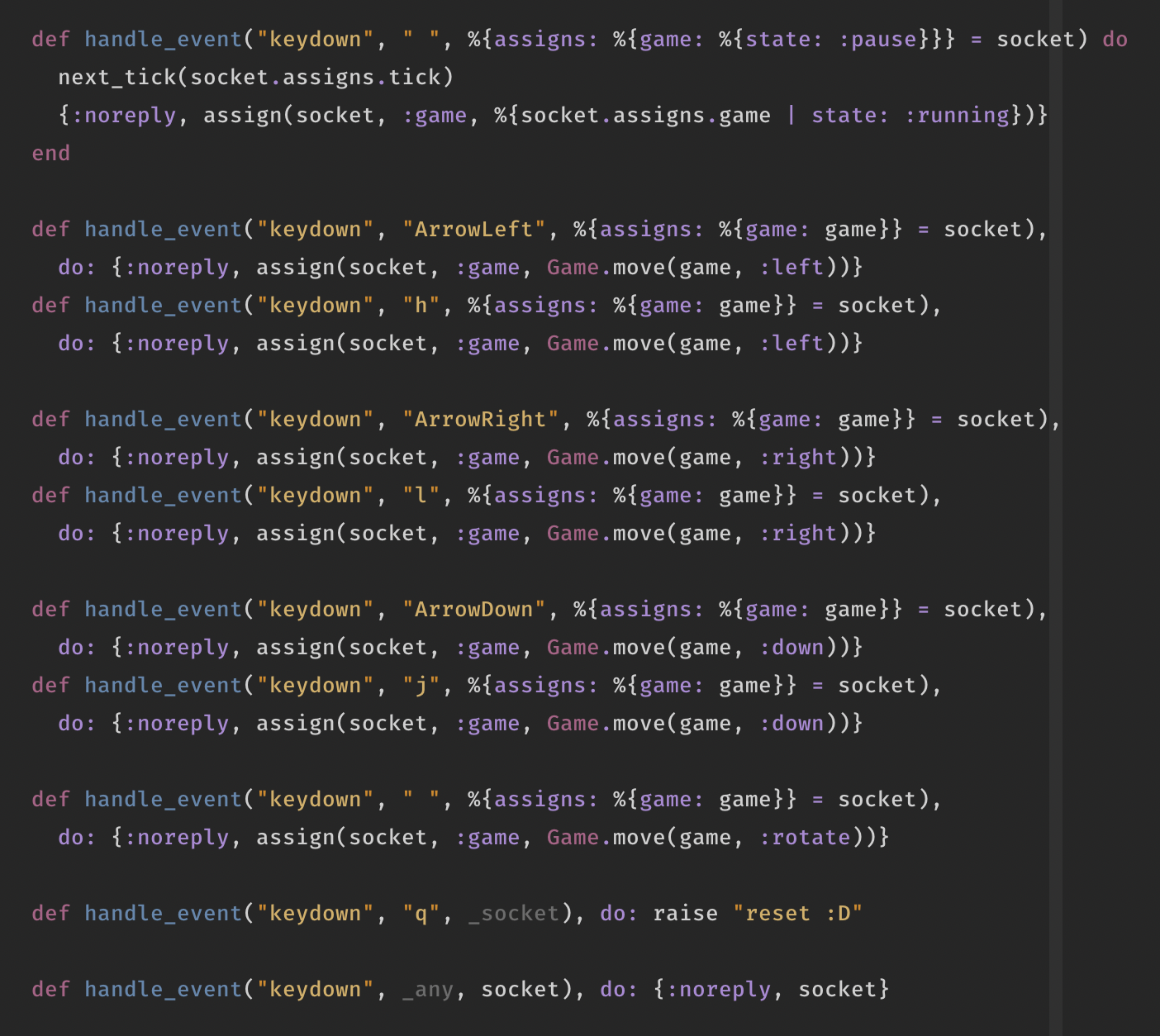
So I wrote this odd-looking piece of Javascript (because it's my day off and I can do whatever) to list out the various perfect scores for the various level-starts.
const killscreen = 19 // or 29
tetrisScore = level => 1200 * (level + 1)
startlevelLines = level => Math.min(
(level * 10 + 10),
Math.max(100, (level * 10 - 50))
)
scoreForLevel = (level, lines) => ({
score: (Math.floor(lines / 4) * tetrisScore(level)),
restlines: lines % 4
})
restlevelScore = (level, rest) => {
if (level >= killscreen) return tetrisScore(level)
const {score, restlines} = scoreForLevel(level, 10 + rest)
return score + restlevelScore(level + 1, restlines)
}
perfectScore = level => {
const {score, restlines} = scoreForLevel(level, startlevelLines(level))
return score + restlevelScore(level + 1, restlines)
}
const levels = [...Array(killscreen).keys()]
levels.map(level => console.log(`| ${level} | ${perfectScore(level)}`))I was kind of surprised by the results: as you can see, the world record by Joseph is higher than the perfect score. This is because he had a 100% tetris rate, burned one line in level 18 for 760 points, then tetrised into level 19, and then made a few singles and doubles in level 19. My definition of 'kill screen' seems too strict, but at least it's even on both sides of the table.
| Start level | NTSC perfect | PAL perfect |
|---|---|---|
| 0 | 1_332_000 | 588_000 |
| 1 | 1_334_400 | 590_400 |
| 2 | 1_340_400 | 596_400 |
| 3 | 1_348_800 | 604_800 |
| 4 | 1_360_800 | 616_800 |
| 5 | 1_375_200 | 631_200 |
| 6 | 1_393_200 | 649_200 |
| 7 | 1_413_600 | 669_600 |
| 8 | 1_437_600 | 693_600 |
| 9 | 1_464_000 | 720_000 |
| 10 | 1_478_400 | 728_400 |
| 11 | 1_454_400 | 710_400 |
| 12 | 1_462_800 | 712_800 |
| 13 | 1_432_800 | 688_800 |
| 14 | 1_435_200 | 685_200 |
| 15 | 1_399_200 | 655_200 |
| 16 | 1_429_200 | 685_200 |
| 17 | 1_461_600 | 717_600 |
| 18 | 1_497_600 | 753_600 |
| 19 | 1_536_000 | |
| 20 | 1_578_000 | |
| 21 | 1_622_400 | |
| 22 | 1_670_400 | |
| 23 | 1_720_800 | |
| 24 | 1_774_800 | |
| 25 | 1_831_200 | |
| 26 | 1_891_200 | |
| 27 | 1_953_600 | |
| 28 | 2_019_600 |
Given that my high score was a level-5-start score of 174_731, I should use ntsc = pal / 631_200 * 1_375_200, giving me a NTSC score of 380_687, a lot more than my previously calculated 230_406. But is this fair now?
Score per second
The table above is not by any means a fair comparison. It does account for the higher scoring potential in NTSC, but it still compares levels regardless of the speed they are played at. Let's combine the previous two tables into one.
So in the PAL version, you get less points, but also less time to think about how to score them. In that regard, the PAL version is harder, and the points should be worth more.
In the next table, I've taken the perfect score per level, and divided it by the thinking time you have for it (the seconds of the earlier table times 240, the number of lines before transition you get when you start in level 29). The result is a series of numbers that say how 'easy' it was to get that number of points.
| Start level | NTSC score | sec / 20 lines | modifier |
|---|---|---|---|
| 9 | 1_464_000 | 1.996 | 3.0561122244 |
| 10 | 1_478_400 | 1.663 | 3.7041491281 |
| 11 | 1_454_400 | 1.663 | 3.6440168370 |
| 12 | 1_462_800 | 1.663 | 3.6650631389 |
| 13 | 1_432_800 | 1.331 | 4.4853493614 |
| 14 | 1_435_200 | 1.331 | 4.4928625094 |
| 15 | 1_399_200 | 1.331 | 4.3801652893 |
| 16 | 1_429_200 | 0.998 | 5.9669338677 |
| 17 | 1_461_600 | 0.998 | 6.1022044088 |
| 18 | 1_497_600 | 0.998 | 6.2525050100 |
| 19 | 1_536_000 | 0.665 | 9.6240601504 |
| 20 | 1_578_000 | 0.665 | 9.8872180451 |
| 21 | 1_622_400 | 0.665 | 10.1654135338 |
| 22 | 1_670_400 | 0.665 | 10.4661654135 |
| 23 | 1_720_800 | 0.665 | 10.7819548872 |
| 24 | 1_774_800 | 0.665 | 11.1203007519 |
| 25 | 1_831_200 | 0.665 | 11.4736842105 |
| 26 | 1_891_200 | 0.665 | 11.8496240602 |
| 27 | 1_953_600 | 0.665 | 12.2406015038 |
| 28 | 2_019_600 | 0.665 | 12.6541353383 |
| Start level | PAL score | sec / 20 lines | modifier |
|---|---|---|---|
| 9 | 720_000 | 1.999 | 1.5007503752 |
| 10 | 728_400 | 1.559 | 1.9467607441 |
| 11 | 710_400 | 1.559 | 1.8986529827 |
| 12 | 712_800 | 1.559 | 1.9050673509 |
| 13 | 688_800 | 1.199 | 2.3936613845 |
| 14 | 685_200 | 1.199 | 2.3811509591 |
| 15 | 655_200 | 1.199 | 2.2768974145 |
| 16 | 685_200 | 0.799 | 3.5732165207 |
| 17 | 717_600 | 0.799 | 3.7421777222 |
| 18 | 753_600 | 0.799 | 3.9299123905 |
This would say an NTSC max-out on a level 18 start is 999_999 / 6.25250501, so has a difficulty of 159_935. The world record on PAL is 758_360 / 3.9299123905, so has a difficulty of 192_971. To me this feels believable, because Joseph has had many beyond-max-out games. We don't know their scores, because the game does not tell us, but their difficulty might also approach 200k.
And my score? Well, as I mentioned somewhere it was a level-5-start score, and as you can see in the first table: there is not much difference between level 9 on PAL and NTSC, and level 5 is not even listed. I should really stop whining and just practice more.
Apples and oranges
If you actually read the article by Tetris Finland you already would know: the speed is not the only difference. There are also differences in the way DAS works in PAL vs NTSC. The article concludes that these games are therefore very different, so different that you might consider them entirely different titles, despite looking the same.
It was fun figuring out these numbers and formula's, but in the end, you really can't compare the two. Gotta fix myself an NTSC somewhere if I want to compare my progress to the pro's.
Note that this difficulty number is a thing I invented in this post, and it is in itself not comparable to Tetris scores. But you can compare it to other difficulty numbers, if you calculate them the same way. Actually, I don't really think this whole thing is reliable at all, but I didn't want to throw a whole morning of calculating and writing out of the window. Some of the tables bear more value than others.