
 Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
Facebook
I went to FOSDEM and all I got was tired.
I went to FOSDEM and all I got was tired.
I was trying to remove the Github Copilot configuration from my Vim setup, but then I noticed it was not there at all. I have been neglecting to commit changes to my dotfiles from my MacBook, as I did not have the courage to share stuff I was just trying out. On my new Linux-based Thinkpad I do in fact commit everything, as running open source stuff makes me want to work in public more too.
But since this config was only in the copy of my dotfiles that now lives on ~/dotfiles-mac, it will get lost now that I don't copy it. A good reason to blog about it.
First: unimpaired is a Vim plugin by tpope, and it is one that should just be part of Vim itself. It adds all kinds of mappings with the [ and ] brackets, and many of them I use daily (most notably [q, [e and [space). The o variant of this will change options, with the special yo binding to toggle the option. I use yoh all the time (toggles search highlighting) and also yol is very useful (shows invisible characters).
I wanted to be able to toggle Github Copilot for the current buffer in this same style. Luckily, the g was still available, and luckily, unimpaired provides an easy way to add new mappings. Unlucky as we are, copilot does not actually provide a toggle, but with Ctrl+R and = in insert mode, we can evaluate some internal options and print a string based on that. See the full command below.
" Going with that flow
Plug 'github/copilot.vim'
" Toggle github copilot
nmap <script> <Plug>(unimpaired-enable)g :Copilot enable<CR>
nmap <script> <Plug>(unimpaired-disable)g :Copilot disable<CR>
nmap <script> <Plug>(unimpaired-toggle)g :Copilot <C-R>=copilot#Enabled() ? "disable" : "enable"<CR><CR>As for why I stop with Copilot? It was very useful in my time at Sneaker District, as I was the only developer working on the project and I wanted to be faster than I was on my own. Having a junior developer in my editor was a nice thing to have: it provided me with good suggestions that I usually had to edit a bit.
But I also noticed it slowed me down at times: I got into the habit of stopping to type to see what it would suggest. And sometimes I just stopped to think, and then it would give me suggestions for directions I did not want to go in. For now, I want to experience less distractions, and get into the habit of typing and thinking for myself again.
(There is also some money involved, and the question whether or not you want to send your code to Github for this purpose. It is nice to have those concerns gone, but it wasn't my primary one.)
It just hit me. I learned how to code via an article in a Dutch school magazine (Taptoe), which explained how to create a website on a floppy disk. They were already old, but at least our computers had the drives still. The article just explained how to write flat HTML, but it was enough to spark this fascination that ended up being my job.
What hit me is that actually most websites these days won't actually fit on a 1,44 MB floppy anymore. (The content on this site already is more than 1 GB.) It would be a nice challenge again, to make a website fit 1,44 MB.
Related to this is the 10 KB Club, who try to keep their homepage under 10 KB. My site fails that test too, but at least the homepage fits a floppy.
I just discovered a new Vim trick I think I am going to use quite often, so I am sharing it here to look it up when I forget.
As you may know, you can issue the / command in Vim to start a search. Every character you type will be in the search, until you hit enter, which will jump you to the first occurance of your searched text.
Another thing you may know, is that you can use this search-motion as a motion to other commands as well. When you do v/here, you will visually select everything between the current cursor position and the first occurance of 'here' in the buffer. I use this to delete stuff that I can't target using the f and t motions.
Then there is the thing I once found out, but never could remember: once you press /, you are in a little submode I can find the name for. In this mode, you can use Ctrl+L and Ctrl+H to increase or decrease your search string by the characters of the first match. You can also use Ctrl+G to move that virtual cursor to the next match, or Ctrl+T to get to the previous. Once you hit enter you are on that last position, removing the need to do n.
But here it comes: when you are deleting with d/, you can also use Ctrl+G to get to that next match. If you searched for a small snippet that accidentally occurs before the place you wanted to go, you can press Gtrl+G to jump over it, and pressing enter will delete the full distance.
I am using PHPStan and the ALE plugin to add some error checking to my Vim. It gives red arrows on lines that contain errors in my currently opened files. But sometimes, in a big refactor, I want to know all errors in my project.
Vim has a build-in feature for this: the quickfix list. It is designed to take the error output of a compiler and lets you jump to all those locations with the :cnext and :cprev commands. I personally use the essential Unimpaired plugin by the one and only tpope, which maps these to ]q and [q.
I use these a lot: the :grep command fills the quickfix list with all the occurrences of your search, like normal grep but with pagination (or, if you set your grepprg to something faster: like ripgrep with pagination).
To get PHPStan to fill this quickfix list, I looked for plugins, but they all seemed hairy. I was convinced this should be simple, and it was. The following leader mapping seems to just work:
nmap <leader>pa :cexpr system('vendor/bin/phpstan analyse --no-progress --error-format=raw')<cr>One thing that always puzzled me a bit about my own workflow, is that almost all of it is based in the terminal (I use Vim and Tmux), except for Git: where most people seem to use the Git CLI commands, I use a graphical program (Fork, which is quite good).
Another thing then: I never used Github professionally, apart from the time I was a self employed web developer, but back then I was the only developer on my projects. All my previous jobs had a self-hosted Gitlab running somewhere.
Long story short: I am trying to get better at Git in the terminal and using Github. And 'better at Git' to me both means 'being able to confidently rebase' as well as 'customise my workflow'.
Customising Git means setting configuration in the ~/.gitconfig file. This file contains settings for Git, like your name and email, but can also be used to add aliases. To create the first alias you can run git config --global alias.co checkout. After this, you can use git co as git checkout, which is shorter to type and yes I use this often now.
Another alias I have is this one:
publish = !git push --set-upstream origin $(git symbolic-ref --short HEAD)If you try to push a branch that has no linked branch on Github (the upstream), Git will complain about it. It will be nice to you and state the command you should have ran, but I got tired of having to copy and paste that new command.
fatal: The current branch feature/new-shoes has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin feature/new-shoesIn Fork, this was just a checkbox away. With my new git publish command I get the convenience again: it will push the branch and set the upstream with the same name as I have locally, exactly as Git suggested I should have done, but in less typing.
So far we have seen two kinds of aliases: one that just aliases a simple Git command (b = branch) and one that actually ran a shell command, because we started it with a ! (note that you will have to start with ! git there). But there is another way: having a command that starts with git- in your path.
I have the following file as ~/bin/git-github, marked as executable (chmod +x ~/bin/git-github) and in my path (export PATH="$HOME/bin:$PATH" in my ~/.zshrc file):
#!/bin/zsh
local url
url=$(git remote get-url $(git remote))
url=$(echo $url | sed 's/.*github\.com[:\/]\(.*\).git$/https:\/\/github.com\/\1/')
if [ -n "$1" ]; then
append="/$1/$(git symbolic-ref --short HEAD)"
fi
open -u "$url$append"Yes, my ZSH is crude. Yes, I can better share this in Bash. Yes, it could've probably been on one line and be included as an alias in my Gitconfig. But it works for me.
The command figures out the Github URL of the project, based on the URL of the remote (it assumes you have only one). It then opens that URL with the macOS open command. If an argument is given, it appends that to the URL, with the name of the branch too.
In my Gitconfig I have two aliases that use this command:
pr = github pull/new
compare = github compareWith git github, my default browser will open a tab with the 'homepage' of the repository. With git compare, it will open a tab that contains a diff of the current branch and the default branch on Github (the remote versions of those). With git pr, the browser will open the correct page to open a for the current branch.
Yes, I actually use the obligatory Tim Pope plugin Fugitive. This means I can do a lot of things which you can also read about in the help file. (Which I read a lot these days.)
But this allows me to stage and commit and rebase and reword all my changes in Vim, and then when I am ready, run :G publish and :G pr and make a PR for it on Github. These two commands alone make me feel so much more productive: no longer do I have to search for another program to compose commits and then search for the browser to handle the cooperative side of it... I just handle everything in my editor.
For Tmux I have another nice addition: in my ~/.tmux.conf I have the following command:
bind-key y display-popup -E -h "90%" "git log --oneline --decorate --graph --all"This will – when I press <prefix> + y – open a popup window, which closes when the command exits and has a certain height. It will show me an ASCII-art style graph of all the commits – one of the features I missed from Fork – as an overlay over my editor, a small keystroke away.
With this configuration – and a lot of reading the Fugitive help file – I feel much more at home with Git in the terminal.
I also watched this fantastic series on mastering Git and these unfortunately dated but still useful screencasts on Fugitive.
I have been wanting to rework the core of this website for a couple of years now, but since the current setup still works, and since I have many other things to do, and finally since I am very picky about how I want it to work, I have never really finished this part at all. This makes me stuck at the save version of this site, both visually as behind the scenes.
Now that I am in between jobs I wanted to work on it a bit more, but I still do not have time enough to fully finish it. I guess it all comes down to a few choices I have to make regarding trade-offs. In order to make better decisions, I wanted document my current storage and the one I have been working on. After I wrote it all out I think I am deciding not to use it, but it was a nice exploration so I will share it anyway.
The description heavily leans on some knowledge about Git, which is software for versioning your code, or in this case, plain text files. I will try to explain a bit along the way but it is useful to have some familiarity with it already.
tl;dr: I did fancy with Git but might not pursue.
At the time of writing, my posts are stored in a plain text format with a lot of folders. It is derived from the format which the Kirby CMS expects: folders for pages with text files within it, of which the name of the text file dictates the template that is being used to render the page. In my case, it is always entry.txt.
I have one folder per year, one folder per day of the year and one folder per post of the day. In that last folder is the entry.txt and some other files related to the post, like pictures, but also metadata like received and sent Webmentions.
An example of the tree view is below. It shows two entries on two days in one year. Note that days and years also have their own .txt file that is actually almost empty and pretty much useless in this setup, but still required for Kirby to work properly. The first day of the year my site is broken because it does not automatically create the required year.txt (or did I fix that finally?).
./content
└── 2022
├── 001
│ ├── 1
│ │ └── entry.txt
│ │ ├── .webmentions
│ │ │ ├── 1641117941-f6bc3209f3f33f0cb8e4d92e5d46b5090b53aa11.json
│ │ │ └── pings.json
│ └── day.txt
├── 002
│ ├── 1
│ │ ├── some_image.jpg
│ │ └── entry.txt
│ └── day.txt
└── year.txtAlso note that there is a hidden .webmentions folder which contains a pings.json for all the sent webmentions and a JSON file with timestamp and content hash in the name for every received webmention. Not in the diagram but also present are some other folders for pages like ./login/login.txt (because that is how Kirby works) and ./isbn/9780349411903/book.txt (for books).
All these files are stored in a Git repository, which I manually update every so often (more bimonthly than weekly, sadly) via SSH to my server. I give it a very generic commit name (’sync’ or so) and push to a private repo on Github, which takes a while because the commits and the repo contain all those images and all those folders.
The main point of wanting to move off of this structure by Kirby, is that it requires those placeholder pages in my content folder. I have no need for a ./login/login.txt: the login page is just a feature of the software and should be handled by that part of the code. But at least that file contains some text for that page: the files for year.txt and day.txt are completely useless.
Another point is that I want to make the Git commits automatically with every Micropub request: Git provides me with a history, but only if I actually commit the files once I changed them. Also, if I do not push the changes to Github, I have no backup of recent posts.
The metadata of the received and sent Webmentions are now also available in the repo. This is nice, as it stores the information right next to the post it belongs to, but on the other hand it feels kind of polluting: these Webmentions contain content by others, where as the rest of the content is by me. There is some other external content hidden in the entry.txt file but I’ll get to that later.
The last point is that the full size images are stored in the repo and every book and article about Git says that you should not use it to store big files in it. Doing a git status takes a while and also the pushes are much slower than any other Git repository I work with.
Before I go further into the avenue I am taking to solve the problem, I need to explain a bit about the Git Object Model, also known as ‘how Git works under the hood’. For a more thorough explanation, see this chapter in the Git Book.
As you’ll learn from that chapter, every object is represented as a file, referenced by the SHA1 hash of its contents. And there are three (no, four) types of objects:
Note that Git does not store diffs, it always stores the full contents of every version of the file, albeit zlib compressed and sometimes even packed in a single file, but let’s not get into that right now.
Git’s tags and branches are just files and folders (they can have / in their names) which contain the hashes (names) of the specific commits they point to. The tags can also point to a tag object, which will then contain a message about the tag (which makes them ‘annotated tags’).
This all brings me to the final point about my storage: for every new post, Git has to create a lot of files. First, it needs to add a blob for the entry.txt, possibly also a blob for the image and blobs for other metadata. Then it needs to create a tree for the entry folder, listing entry.txt and if present the filenames of the images and metadata files. Then it creates a new tree for the day, with all the existing entries plus the newly created one. Then it creates a new tree for the year, to point to this new version (tree) of the day. Then it creates a new tree for the root, with this new version of the year in it. And finally it also needs to create a commit object to point to that new root tree. Every update requires all these new trees. The trees are cheap, but it feels wasteful.
Also note that a version of a file always relies on the version of all other files. This is what you want for code (code is designed to work with other code), but it does not feel like the right model for posts (I might come back on this tho).
And there is also the question of identifiers: currently, my posts are identified as year, day of year, number (2022/242/1), but especially that number can only be found in the name of the folder and thus in the tree, not in the blob. I have not yet found a good solution for this, but maybe I am seeing too many problems.
To get rid of some of the trees, I tried to apply my knowledge of the Git Object Model to store my posts in another way. To do this, I used the commands suggested by the chapter in the Git Book in a script that looped over all my files, to store them in a new blank repo to try things out.
For each year, for each day, for each post, I would find the entry.txt and put the contents in a Git blob with git hash-object -w ./content/2022/242/1/entry.txt. The resulting hash I used in the command git update-index --add --cacheinfo 100644 $hash entry.txt to stage the file for a new tree. I would do that too for all images and related files, and then I would run git write-tree to write the tree and get the hash for it and git commit-tree $hash -m "commit" to create a commit based on it (with a bad message indeed). With that last hash I would run git update-ref refs/heads/2022/242/1 $hash to create a branch for that commit. (I contemplate adding an annotated tag in between, for storing some metadata like ‘published at’ date.)
This would result in a Git repository with over 10,000 branches (I have many posts) neatly organised in folders per year and day. When one were to check out one of these branches, just the files of that posts will appear in the root of your repo: there are no folders. When you check out another branch, other files will appear. This is not how Git usually works, but it decouples all posts from one-another.
The posts I describe above all follow the year-day-number pattern because they are posts: they are sequential entries tied to a date. There are other objects I track, though, that are not date-specific. One example is topical wiki-style pages: these pages may receive edits over time, but their topic is not tied to a date. (I don’t have these yet.)
Another example is the books that I track to base my ‘read’ posts off. I haven’t posted them in a while, but I would like to expand this book collection to also include other types of objects to reference, such as movies, games or locations. These objects also have no date to them attached, at least not a date meaningful to my posts.
I could generate UUIDs for these objects and pages, and store branches for those commits in the same way Git does store it’s objects internally, with a folder per first two characters of the hash (or UUID) and a filename of the rest:
./refs/heads
├── 0a
│ ├── 8342d2-d6f1-4363-a287-a32948d04eaa
│ └── edcb13-433c-48d2-b683-a407c3a88f57
└── 3d
├── 243a27-114e-4eee-9bd8-2a51b01939e6
├── 25965b-2da5-422d-abce-f3337fa97fc4
└── 611b59-499a-48a0-b931-afe06192e778I could even reference the same post/object with multiple identifiers this way. Maybe I want to give every book a UUID, but also reference it by its ISBN. The downside to that, however, is that I need to update both branches to point to the same commit once I make an update do the book-page.
The multiple identifiers are probably not feasible, but there are some other drawbacks too. My main concern is that it is much harder to know whether or not you pushed all the changes: one would have to loop over all 10,000+ branches and perform a push or check. In this loop you would probably have to check out the branch as well. It is of course better to just push right after you make a change, but my point is that the ‘just for sure’ push is a lot of work.
Another drawback is actually the counter to what I initially was seeking: wiki-style pages might actually reference each other, and thus their version may depend on a version of another page. In this case, you would want the history to capture all the pages, just as the normal Git workings do. My problem was with the date-specific posts, but once you are mixing date-specific and wiki-style pages, you might be better off with the all-file history.
One problem this whole setup still does not solve is that of large files. The git status command is much faster for it does not have to check all the blobs in the repo to get an answer, but the files are still in the repo, taking up space. And there do exist other solutions for big files in git, such as Git LFS, the Large File Storage extension.
Also, I am still not 100% sure it is a good idea to store metadata in the Git commits and tags. When we already store the identifier in the tree objects, I thought I could also add the ‘published at’ date into the commit. Information about the author is already present, and as my site supports private posts, it also seemed like a reasonable location to store lists of people who can view the post. But again, maybe that should be stored in another way, and not be so deeply integrated with Git.
It was very helpful to write this all out, for by doing so I made up my mind: this is just all a bit too complicated and way too much deeply coupled to Git internals. I would be throwing out the ‘just plain text files’ principle, because I would store a lot of data in Git’s objects, which are actually not plain text, since they are compressed with a certain algorithm.
My favourite Git GUI Fork is able to work with the monstrous repository my script produced, but many of the features are now strange and unusable, because the repo is so strangely set up. I would have to create my own software to maintain the integrity of the repo and that could lead to bugs and thus faulty data and maybe even data loss.
I still think there are some nice properties to the system I describe above, but I won’t be using it. But I learned a few new things about Git internals along the way, and I hope you did too.
As I don’t use a full IDE like PHPStorm, I don’t get much help with the parameters to function calls from my editor. On one hand I find this a good thing: IDE users rely so much on autocomplete that they don’t remember names of things at all. On the other hand: who has the mental space to waist on such things?
My middle ground is that I look up a lot of things on PHP.net. They make that very simple: just add the name of the function you are looking for after the slash and they will give you the correct documentation. But: switching to a browser and typing out the address requires a lot of keystrokes. I found a solution.
nmap <Leader>pd :silent !open https://php.net/<c-r><c-w><cr>This adds a leader key mapping to look up the word (so: function name) under the cursor. I prefix all my PHP related leader mappings with a p, but feel free to pick something else.
The :! runs a shell command, in this case open, which on Mac can be given a URL, which will then be opened in the default browser. I added silent to ignore the output of the command: I just want to open a URL.
As the URL, I let Vim type out the address to PHP.net, and since we are in command mode, one can do Ctrl+R, Ctrl+W, which will paste the word that is currently under the cursor (very nice to know in itself). We end the sequence with an enter (carriage return) to run it.
So the tip within the tip is Ctrl+R (register) Ctrl+W (word). In general Ctrl+R in insert mode gives you this interesting ‘paste from register’ mode that is good to know. See :help i_ctrl-r and :help c_ctrl-r for more.
When @hacdias.com posted about our conversation about post topics I couldn’t stay behind to also formulate my part of it in a blogpost.
Currently I have various feeds for various post types. I don’t want to link them all here, in case I want to change them around, but I have different feeds that only show my likes, my photos, my replies, etc (you can probably guess the URLs).
These feeds are relatively easy to set up: does it have a photo? Then it’s a photo. Does it have a title? Then it’s an article. This post doesn’t have any, so it’s a note. I have a few of those rules set up and they fill these pages.
But when you scroll through my photo feed, you will also see drawings. When you scroll through my notes, there are various topics represented. It is not that bad right now, but that is mainly because I don’t post as much as I could, because I don’t want to bore my readers with topics they don’t want to follow.
On social media, we live a siloed life, and the people on the IndieWeb are trying to bring that all back to their own site. But, in the siloed life, we can pick the silo for the post. ‘Insta is for friends, Twitter is more business, Reddit is shitposting’, something like that. Sometimes the silo is aimed at a certain kind of post, sometimes it is just the kind of bubble you created for yourself on that silo that makes you post a certain way.
On the IndieWeb, I have only one site. Of course I can get multiple – I have – but I like having all my posts in one place. But I also want to give people options for how to follow me, different persona to share posts with.
I do have tags but most are not that useful. Most of them only contain one post, and also, most of them are very specific. I like the indieweb and vim tags, for they are quite topical, but those are exceptions.
At one point (not now) I would like to divide posts up into probably five rough categories. The homepage might still show a selection of all, and there will also be a place to actually see everything, but I think these categories make sense to me:
I said five and I posted four, because I don’t think this is final. I might also want to add a ‘current obsession’ category, to blog about those things I am deeply into. (There has been posts about keyboards here, you missed Getting Things Done, currently I am into the game of Go again.)
A last category I might also need is ‘thinking out loud’, as this is a post that would fall into that. For what is worth, I’ll post it anyway.
tl;dr: I just mapped Y to "+y and I am very pleased with it.
A coworker saw me copying some text out of Vim and humored me: everything seemed to happen like magic in my editor, but for a simple thing as copy and paste I needed a lot of keys.
It is true: in order to copy text within Vim, you can use the y command, combined with the motion of what you want to yank. So: yiw will yank inside a word, ggyG will go to the top of the file and then yank until the bottom (so, the whole file), yy will yank a full line. But these yanks are only pastable (with p) within Vim itself.
In order to get text out of Vim, you need to use a special register. Registers are a sort of named boxes, letters a to z, in which you can put snippets of text. To use it, you prefix your yank (or delete) with a quote: "ayi( will select register a and then yank the text within parentheses. To get to your system clipboard (the one all other programs use), you select the special register with "+.
Thus: my coworker saw me hunting for the "+y combination, probably. I almost always look at my keyboard when I do that, so awkward is the combination. But I just found a solution: Y.
nmap Y "+y
vmap Y "+yBy default, Y does a yy, which I never use, because it's inconsistent with other commands. D, for example is equivalent to d$, delete until the end of the line, same for C as c$. I guess it makes Y play along with V (line-wise visual select) and S (subsitute full line), but I always use yy anyway, so Y is free to use. When I now want to yank to my system clipboard, I just use Y instead of y and that's it.
You can also consider adding this as gy, which does not have a meaning, but g combines with various commands to activate variation of their meaning, so it's not a bad choice either. I mapped it to both and will see which one sticks.
Today we needed to add a TailwindCSS prefix to a small project we are building, to prevent clashes with other TailwindCSS classes on the same page. The setting in the tailwind.config.js was straightforward, we added this:
module.exports = {
prefix: 'sf-',... and now TailwindCSS will generate classes like .font-bold and .border-none as .sf-font-bold and .sf-border-none. Next up, we needed to replace all the classes in the project with their prefixed counterpart.
There were some plugins available to do this automagically in Webpack, but we decided we wanted to add them manually. A few of the classnames are dynamically set, and we doubted the plugins would find all those cases. Also: the plugins seemed to be old.
My co-worker started writing a regex for a search-and-replace, but soon stranded. You need to find the proper locations, and then within those locations, add the prefix. The prefix, however, is sometimes more of an infix, since there are other prefixes that are added before the prefix itself. See the class with md: for example:
<div className="bg-gray-100 px-4 md:px-0">
// Becomes:
<div className="sf-bg-gray-100 sf-px-4 md:sf-px-0">While he worked on the regex and subsequently went to get coffee, I thought: I should be able to solve this in VIM in some way. I know I can make a visual selection and then type :! to get the selection as input into some shell command. If I pipe the lines to some script, I can then just split strings all I want.
One problem I ran into was that, if I make a visual selection within quotes (vi") and I then use the colon-exclamation to pipe it to some script (:'<,'>! php transform.php), I will receive the full line, as if I was using the line-wise V selection.
While searching the internet I thought: can I use a register here? And the internet had a solution for that. I ended up running the following command:
:vmap m "ay:call setreg('a', system('php transform.php', getreg('a')))<cr>gv"apThis sets up a mapping for visual mode, and binds the m to do a series of things. It first selects the 'a' register and yanks ("ay). Since we are already in visual mode here, y is a direct yank of that selection. We are now in normal mode, so we continue to type out a command that calls a function to set register 'a' again with the output of a system call to php transform, taking in the current contents of register 'a'. We execute this command by pressing enter (<cr>). Register 'a' now contains the scripts output. We then re-select the last visual selection (gv in normal mode) and then paste from register 'a' ("ap). This effectively runs the script over the visually selected area.
I then just opened the alphabetically first file of the project and manually made visual selections that selected all the classnames. For this, I also temporary mapped m to vi", so I could just do mm once my cursor was in a className="..." (for which mouse mode is nice too: click + mm, very fast). Then, to get to each next file, just press ]f.
The project was small enough to do this last part so manually, but this at least saved me a lot of stops in between all the classnames, and also saved me the headache to scan for md: prefixes and pick the right spot. Even when the classnames were actually in a backtick-string it was no problem: as long as I defined a correct visual selection, m would replace things.
For completeness, here is transform.php:
<?php
$input = file_get_contents('php://stdin');
$classes = array_filter(explode(' ', $input));
$classes = array_map(function ($class) {
$parts = explode(':', $class);
$parts[count($parts)-1] = 'sf-'.$parts[count($parts)-1];
return implode(':', $parts);
}, $classes);
echo implode(' ', $classes);Nice to hear you are enjoying the series! (It turns out to be a series.) It also feels really good to have finally found a form again where I can cycle between writing code and writing blog posts about the code.
Looking forward to read your article && yaay it worked!
Edit: lol, next topic really is Webmentions: I had to manually send this one because I am certainly not parsing HTML with regex (I would never) and your rel has no quotes around it.
Next up must be Webmentions, I feel. I just posted this article with a lot of backlinks to old posts, but since I send all Webmentions in a synchronous way on first-post-visit, it took ages, and I actually got a 502 Bad Gateway out of my site. But I also need weekend, so we will see.
In February 2017, I added the ability for other people to log in to my site, both via IndieAuth and Twitter. Since June 2019 this feature is more useful, as I moved all my checkins to being ‘private’, meaning there is actually something to see (albeit sparsely posted).
For this, I used the now outdated and deprecated service IndieAuth.com, which back then was also used to log in to the IndieWeb wiki. Due to the confusion between IndieAuth.com (the service) and IndieAuth (the protocol), a new project called IndieLogin was started and the IndieWeb wiki moved to that one. Since it didn’t offer that login service to others, as IndieAuth.com did, I never switched.
Since this week I have a new IndieAuth endpoint for myself. (Meaning: a place I can use to prove my own identity to others.) Unfortunately, it is not compatible with the outdated IndieAuth.com, so I could not use it to prove my identity to my own site. Because this felt wrong (and because I had the IndieAuth flow in my head again now), I decided that my site needed to do that part of IndieAuth on it’s own as well.
Since I was at it, I also have Twitter login working via the new flow. That was easier, because the library support was more plug-and-play.
Last week I wrote about my new setup where I run two applications, the old PHP and the new Elixir, behind an unusual NGINX configuration. For the aforementioned feature of authentication, I had to create even a bigger beast.
All the posts, and all the logic for showing or hiding private posts, are still in PHP. The new authentication is in Elixir. Both ends are storing the information about the current logged-in user in session cookies. How do I merge those two into one user experience?
Luckily, since both applications run under the same domain, the browser is actually unaware of the fact that there are two apps. It just sends all cookies back.
So, in PHP I ask for all headers, look for a cookie-one that is named _yak_key, and if it is there, it makes a direct localhost call to Yak, the Elixir server, with that cookie. Yak exposes one route that just returns the currently logged-in user as a JSON. If that call returns a user, PHP can set a cookie of its own.
Then for the logout, PHP used to redirect to the homepage, but now it redirects to the page that logs you out of Yak, which redirects to the homepage.
At some point this setup will change again, but for now it seems to me as a good way to make one further step in the features I want to support in the new version of my site, while keeping the old one running.
Oh yeah, you may hunt down that localhost-call that checks the login status. It is actually exposed to the outside world too. But if you can provide it with a cookie for a person that is not you, that person and I have a problem anyway, regardless of you knowing the endpoint.
Last Thursday I started using my new IndieAuth endpoint, which I can use authorize apps build by others (like the Quill Micropub client), to do stuff with my site (like posting this blogpost for example). In the following weekend I added a lot more validations than just my password, making it a safer endpoint.
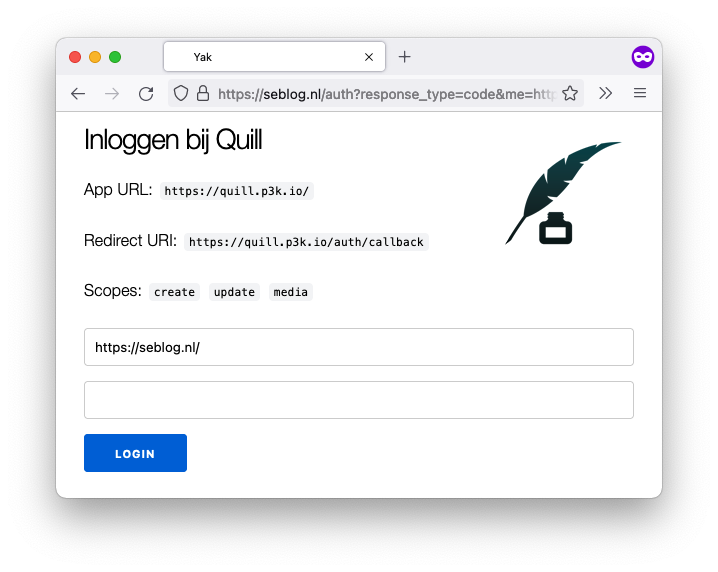
One of these validations is the redirect_uri. My previous endpoint already showed this to me on the login-page, so I could manually inspect it, which is a good practice. The spec, however, describes that one should fetch the client_id (which is a URL) and look for a link with the rel-value of `rel="redirect_uri", which can be either in the HTML or in the HTTP Header.
So this is what it (currently) normally looks like:
And this is what it looks like when the redirect_uri differs from scheme, domain and/or port, and is also not present in at the client_id.
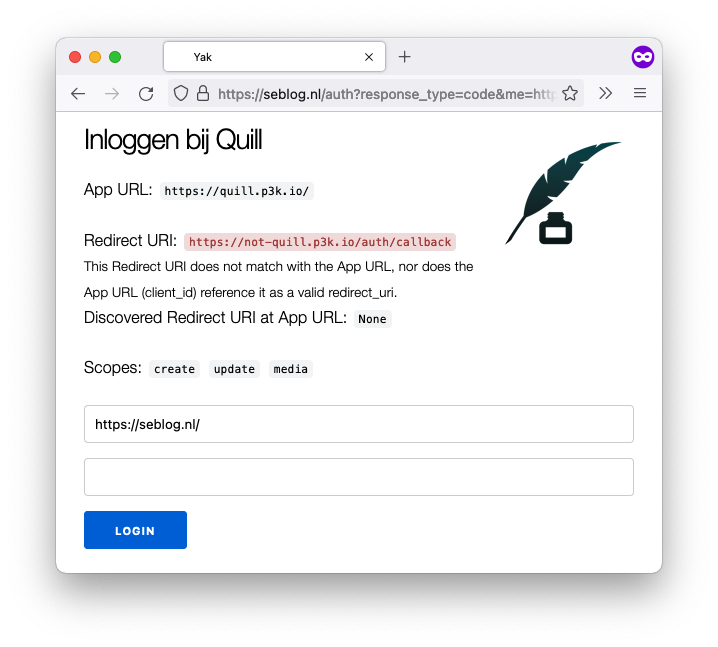
Note that it is okay for Quill not to advertise another redirect_uri, for it is redirecting to a URL with the same scheme, domain and port. It only needs to add the link if it wants a URL where one of these are different. It is now clearer that someone who is not Quill is trying to steal a token.
At the time of writing this blogpost, my site is written in PHP, and most of the code is many years old. One could call it a legacy application: I was not very good at organising code back when I started it, so it is a bit of a mess.
Like any legacy application, rewriting it would be costly. There are many features I don’t want to lose, but at the same time I don’t want to lock myself up and rewrite them all before I can show and use any work. This kind of ‘Big Bang release’ would eat up all my free time for the next months and my motivation probably won’t make it all the way through.
Yesterday I attended the first IndieWebCamp since ‘March 2020’ and I didn’t want to come empty handed. I forced myself to start a new project called Yak.
This is actually the fifth project called ‘Yak’ on my system, but it’s the first one I actually deployed. All the Yak-projects focus on a different part of the app, since there is always something you think you should do first before the rest can start.
The newest and deployed Yak consists of a new IndieAuth endpoint. I was able to shave off this part since IndieAuth tries to be decoupled from the rest of the site: its endpoint might even be on a different domain.
I didn’t go that route though: I decided to strangle.
With ‘strangle’ I refer to the ‘Strangler Pattern’, after the now more friendly(?) Named term ’Strangler Fig Application’ by Martin Fowler. This plant grows around another tree, slowly taking over its shape and killing it in the process, so that eventually, all that remains is the fig.
In terms of Seblog.nl, I would like Yak to take over more and more features from the PHP-version, until finally Yak is my new CMS. I say ‘PHP-version’, be because yes, Yak is written in Elixir now. How would I go about taking over features then? My first attempt was this:
index index.html index.php;
location /auth {
# ... proxy headers
proxy_pass http://localhost:4001;
}
location / {
try_files $uri $uri/ index.php$is_args$query_string;
}
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_index /var/www/seblog.nl/index.php;
fastcgi_param SCRIPT_FILENAME $request_filename;
fastcgi_param PATH_INFO $fastcgi_script_name;
include fastcgi_params;
}That’s a pretty normal PHP setup, but with one path as a proxy. Yak is listening to port 4001 and NGINX sends all traffic for /auth and sub-folders to it. (A firewall keeps visitors for 4001 from outside away, don’t worry.) This way I can have my IndieAuth endpoint be in a different application while still maintaining one domain to the outside.
But since this is my hobby project, I can get niftier.
The IndieAuth route is fairly well scoped and easily separated from the rest of the app. For creating posts via Micropub, I can also separate a route and then store the created posts in the same file folder (or database) since both apps run on the same machine. But not all features are that easily separated.
To make it myself easier to add new routes to Yak, I created the following monster:
index index.html;
location @yak {
# ... proxy headers
proxy_pass http://localhost:4001;
proxy_intercept_errors on;
error_page 404 = /index.php$is_args$query_string;
error_page 502 = /index.php$is_args$query_string;
}
location / {
try_files $uri @yak;
}
location ~ \.php$ {
# same as previous PHP
}Since Yak is pretty fast (the Phoenix framework logs its response times in microseconds instead of milliseconds), I decided to just route all traffic through Yak. If Yak has the answer, that answer will be the final answer. But all routes that get a 404 Not Found error from Yak, are given to PHP afterwards.
This way the old site still functions: PHP is not even aware that someone has looked at the request before it. I also added the 502 Bad Gateway just in case Yak is down, which I expect only to happen for brief moments during big configuration changing deployments.
A few details to note: it all starts by adding @yak as a final location to try_files. Only the last location can be a virtual one, otherwise I would have put PHP directly in that list. I did remove the $uri/ and removed index.php from the index directive at the top: without this the homepage was not delivered to Yak.
The other crucial bit is the proxy_intercept_errors on, because that traps the errors in the proxy and enables you to add cases for certain errors. With error_page 404 = /index.php$is_args$query_string I send them to PHP. Other errors from Yak, like 401 and 403, are still just rendered as they came from Yak.
While the above does work for most of my site, it broke my Webmentions and Micropub. (Yes, I tried posting this a few hours ago.) The previously described method makes all requests in PHP come in as GET, which makes sense for rendering an error page.
After a lot of trial and error, reading NGINX documentation and even trying to get Yak to proxy, I decided to localise the few POST requests I needed to be PHP and added those explicit in NGINX.
location /webmention {
try_files $uri $uri/ /index.php$is_args$args;
}
location /micropub {
try_files $uri $uri/ /index.php$is_args$args;
}Once I moved these endpoints to Yak, I can remove them from my NGINX.
So, I am not in London and I am not even in the precise timezone as London, but since The Situation is still keeping us home, I got to attend Homebrew Website Club London.
It was mostly just some chatting about smoke detectors, automated blinds and visits to city water reservoirs, as one does on a HWC. We had a few on-topic points as well.
I told about the upcoming birthday of Seblog.nl, tomorrow, which got us down the path of looking up old versions of websites. Much is saved, but many things are lost as well. One thing we came to: if you are starting to code your own website, please learn how to use version control as soon as possible. I (and others) have lost old versions of our sites because we kept overwriting the old files with new changes. If I had discovered Git (or any other version control) earlier, I would have had the oldest versions still.
As a note to myself: I should read Peter's article that he mentioned, which is about this 'content archeology': bringing back old home-pages. I doubt I have enough time to excavate my own first version of Seblog.nl before tomorrow.
Calum also showed his new bookshelf page. It reminded me of my own page called /bieb (short Dutch for 'library'), and now I want to revisit that page as well. The past month, I've been playing around with Obsidian and this would be one of those places where my site could integrate with it. (Both Obsidian and the current iteration of my site run on raw text files.)
I also shared some of my plans around this integration but I am not ready to share those here. (Most of my projects become vaporware, sadly.) However, I feel encouraged that my idea was not totally a bad idea. (Only slightly.) That's why I like going to HWC's: they spark ideas and / or bring them further.
The reason I follow your lessons is exactly because they are in Japanese!
You just learn more Japanese by using it.
It was about Zelda, I believe, and I kept it on a floppy instead of a server. It had a “secret page”, which was linked from one of the letters of a page header. It was a pretty obvious link though: I had no idea how to get rid of the underscore with just HTML.
VIM productivity is a lie: all the time you save with your fancy commands and macros, you loose again on bragging about them to your coworkers.
Watching a livestream by @jlengstorf and @waterproofheart trying to make Bridgy work on a Netlify app. Lot of debugging still, with unhelpful errors.
Edit: they just brought next-netlify-webmention.com to solve the problem.