At IndieWebCamp Berlin this year, at the session about Workflow, we came up with an idea, how to enhance your blogposts with an external service using Micropub. I’ve thought of a few variants, and in spirit of the IndieWeb I should first build them and then show it, but I haven’t got around it yet.
So y’all will have to do with just a description. I might implement it at some point, if I have a real use case for it. I don’t actually want weather on my posts.
But let’s start at an idea I first had at IndieWebCamp Nürnberg.
The Syndication Button Hack
Micropub is an open API standard that allows clients to post to servers. In the spec, there is a mechanism for clients to show buttons for syndication targets. The client asks the server what targets there are, and the server responds with a list of names and UIDs. The client then shows the names on buttons (or near checkboxes) and if the user selects one, the UID is set as the mp-syndicate-to field of the post. The server is then responsible for syndicating the post to, say, Twitter or Facebook.
This mechanism is widely supported among clients. And since the client does not have to do any work actually related to the syndication, it can also be used for other things.
Imagine the server implementing private posts. The support for private posts in Micropub clients is not really existing at the moment of writing. But we can get a button to toggle the state of the post created, quite easily:
Since it’s up to the server to syndicate to private-post, it can decide not to syndicate it, but to mark it private. There are a number of possibilities with this: toggle audiences, mark the post as draft. All these things could have their own queries at some point, but until then, this will work in almost all the clients.
Also notice the Bearer token. The server can know which client is asking, so it could show a different set of buttons, depending on the client. Quill supports draft posts? Don’t show that button in Quill.
Enter the Weather Service
Back to the idea of Berlin, which takes this one step further. If we have the Syndication Button Hack in place, we can also hook up external services to enhance our blog posts.
Say I display a location with every entry I post. I could have a button that says: ‘Weather Service’. Activating that button would instruct my server to ping the Weather Service about the existance of this new post. This could be done by WebSub or some other mechanism.
Back when I signed up for the Weather Service, I gave it access to my Micropub endpoint as well. The Weather Service waits for new posts to arrive, reads their location, fetches the weather for that location, and sends a Micropub update request.
The only new part this requires, is the button and the ping to the Weather Service. All the other parts exist in clients and servers. Ah, and someone will need to build that Weather Service.
External services in general
The nice thing about this model, is that the heavy lifting is on neither the Micropub client nor the server. It’s on the external service. And it’s not that heavy of a lifting, because the external service does only one thing and does one thing well. It can give superpowers to both Wordpress blogs and static generated sites.
The external service could provide information about the weather, but think of Aaron’s Overland and Compass: it could also provide the location of the post given a point in time. There might be more. Expanding venue info?
One thing to watch out for, is concurrent processing of these Micropub requests. This might not be a problem for you, but I store my posts as flat files. If two services send an update request for the same post, one might start, and the other might overwrite the first one. (I really need to check how my blog handles this case.)
When you are using a database like MySQL, you should be safe for this kind of stuff, but it still depends on the implementation of your Micropub endpoint.
Other ways of doing it
Peter did not like this first approach, because his post would have multiple visible states (first a few seconds without weather, then with it).
Another appreach would be a sort of Russian doll Micropub request, where you sign in to an external service which signs in to your Micropub endpoint. This would mean that quill.p3k.io posts to weather.example/micropub which intercepts the request, and sends the same request with weather info added to seblog.nl/micropub.
I don’t like that approach either, because now I have to trust the Weather Service with my tokens. In the first approach, every service gets their own scoped token, which is safer.
Since the server knows how many services it has asked to enhance the post, it could also keep it in draft until the last update request comes in. This would require more work on the server’s side of things, and there has to be a timeout on it, but it could be a way to mitigate Peter’s problem.
As always: feel free to steal or improve, but please let me know.
Recently I’ve been to IndieWebCamp Berlin, where I spend the Hack Day on abusing the PushAPI to update ServiceWorker caches.
I would like to start with a small section on what and why, but while I was procrastinating on writing this blog post (the pressure is high), no one less than Jeremy Keith wrote a blog post about it. Since that’s a perfect what and why, there are just two things to do for me here: demo and how.
Demo
I did a demo in Berlin, but the demo-gods where unforgiving. It did not work at all, but when I got back to my seat, it started working again. What happened? My Mac tried to be nice and turned off notifications while I was presenting.
But, as to make up for it, the new macOS Mojave shipped with a screen capturing tool. So here is a retry of the demo in under 5 minutes:
The how
This might not be the most interesting part of it, but it’s nice to share work. It’s not a full comprehensive guide on how to do this stuff, because that would just take way too long. See it as a quick guide behind the different API’s involved.
I googled it all anyway. You can google along.
Oh and if you want to skip ahead: there are some use cases at the end.
Showing a local notification
Like with any Javascript, you should check support before you ask something. There is a list of things to ask in the below code example: we want Notifications, it should not be denied, there has to be ServiceWorker support, and for the part later on, there should be a PushManager too.
Once we prompted the user and got permission, it’s as simple as getting our ServiceWorker registration and ask it to show a notification. As you can see: this involves the ServiceWorker, but it does not involve any other servers.
function activateNotifications() {
Notification.requestPermission()
.then(status => this.status = status)
},
function supportsNotifications() {
return ('Notification' in window) && (this.status !== 'denied') &&
('serviceWorker' in navigator) && ('PushManager' in window)
}
async function sendTestNotification() {
const reg = await navigator.serviceWorker.getRegistration()
return reg.showNotification('Hallo, test!')
}
Note: the demo code is using Vue, which I leave out in this blog post to simplify things. But that’s where this points to: a collection of variables on the Vue instance.
Subscribing for the PushAPI
Once the user clicks the button ‘Subscribe’, the following function gets triggered. In here, we again get the ServiceWorker registration, and then access the PushManager on it, which we tell to subscribe.
Some browsers have their own way of doing authentication, but the most universal is with a Vapid key pair. The package I use for the backend came with a way of creating them. We give the public key to the PushManager, which will give us a Subscription object.
In the end, we send the Subscription’s key, token and endpoint to the server via a POST request.
Note: my HTTP library of choice is axios and the urlB64ToUint8Array() function can be found here
Storing the Subscription
For the backend, I’m using a Laravel package for WebPush, which allows me to save the endpoint with very minimal code:
public function update(Request $request)
{
$this->validate($request, ['endpoint' => 'required']);
$request->user()->updatePushSubscription(
$request->endpoint,
$request->key,
$request->token
);
return response()->json(null, 201);
}
As you can see, it is using the user to associate the data with. (I fake the auth in the demo, which I do not recommend.) It ends up in a database, with four main columns: user_id, endpoint, public_key, auth_token.
In theory, you can go without users, but you will need to store the other parts. The token and key look like random strings, but the endpoint is an actual URL, on a subdomain of either Mozilla or Google, depending on the browser. (No support on Safari yet, mind you.)
These endpoints and tokens can expire, so you will need to keep an eye on the table.
Sending the notification
I can be short about this part: I have no idea. The following code is all it takes to trigger it:
Notification::send(
User::all(),
new NewBlogPostCreated($content, $notify)
);
... where $content is the content of the post, and $notify a boolean, telling my ServiceWorker whether or not to show a notification (we’ll get to that).
The NewBlogPostCreated class extends Laravel’s build-in Notification class and has these two methods:
public function via($notifiable)
{
return [WebPushChannel::class];
}
public function toWebPush($notifiable, $notification)
{
return (new WebPushMessage)
->title($this->notify ? 'notify' : 'update-cache')
->body($this->content);
}
There is a lot of magic behind the scenes here. I have no idea. In the end, they send a POST request to the endpoints of those users, after signing the right things with the right keys.
Receiving the notification and then don’t
Next, we’re back in Javascript-land, however, this is the ServiceWorker-province. The ServiceWorker, once installed, is a script, written in Javascript, but completely decoupled from any window. It lives in your browser and represents not one page, but your whole website.
It’s quite hard to wrap your head around at first, but, I think the PushAPI makes it easier: there is no window involved with a push message, and there is no page involved with a push message. There is only your ServiceWorker, which acts for your whole website.
The ServiceWorker script itself consists of a series of callbacks, that are executed whenever things happen. In the case of a push message, the 'push' event is triggered:
(function() {
'use strict';
self.addEventListener('push', function (e) {
const data = e.data.json()
self.caches.open('manual')
.then(cache => cache.put('hello', new Response(data.body)))
if (data.title == 'notify') {
e.waitUntil(
self.registration.showNotification(
'New content!',
{body: data.body}
)
);
}
});
})();
That’s all I need for receiving push notifications. I first retrieve the data from the message. Then I open the cache named ‘manual’ and I put the body of the message in that cache as the content of a URL (in this case ‘offline.test/hello’). It is made for pages, but I use it as a key-value store here.
Then I check the title field, which I have abused for this purpose. If it is set to the magic string ‘notify’, I will trigger the notification. If it’s something else I will do nothing.
This shows that I don’t have to: I can leave the notification out, but I still get a ServiceWorker activation and I can do whatever I want with it.
Use cases
I think this can be used for creepy things (can I occasionally ping my ServiceWorkers and ask for data like ‘how many windows are open?’ and phone that home?), but I also think there are nice uses for this as well.
As Jeremy wrote: this can be used for magazines, podcasts and blogs to push new content to my phone, to read on a plane or in the subway when I’m offline. I see a nice feature for a web-based IndieWeb Reader too: it can push me copies of posts it collected.
I think the Reader is a nice place to use this. With great power comes great responsibility. Do I want to grand that great power to that weird magazine, that dubious podcast, that blog I visit once or twice a month? I might know you well, I might not. Do I trust you, pushing megabytes on my phone without me noticing?
Web apps like a Reader are easier to bond with. Plus: once I know my Reader supports reading offline, I might visit it in the subway. Will I remember the magazine?
The last bonus of the IndieWeb Reader specifically: it can send me posts from any magazine or podcast or blog, whether they support offline reading or not. But that’s more specific to the Reader than it is to Push.
I’m also very curious to know how things will evolve if ServiceWorkers get even more superpowers. How well will those pair with a free ServiceWorker activation? Lot’s of exploring to do!
Apart from the question how to fetch private feeds, there is also the question how to present private feeds. The easiest way is probably to give every user their own feed, containing only the private posts for them. They can separately follow your public feed, and your queries are easier.
But in line with Silo’s like Twitter and Facebook, I think I would prefer presenting one feed, with both public and private posts, scoped for the authenticated user. When I described this to Aaron he said that he liked it, but that he didn’t know where to begin with writing code that does that. I didn’t either, but it made me want to explore the possibilities.
On a sidenote: this feed design also raises another problem, of how to signal to the user that they can see this post but no-one else. I leave that one for another time.
Drawing rough lines around boxes
Borrowing from Facebook, there are roughly four categories you can share content in:
public – These posts can be seen by anyone. This is the default on nearly all IndieWeb sites today.
authenticated – These posts can only been seen if you sign in, but, anyone can sign in. Facebook has this category and we can mimic that with IndieAuth, but it might not add that much value.
friends only – This is a big category on Facebook, and made possible by the friendslist, which is also a big feature on Facebook.
selected audience – Facebook also allows you to pick your audience on a per-post basis. This can be done by either selecting individual users, or selecting lists, which can contain users.
There is also the possibility of excluding specific people or lists from posts, but that one is even more advanced, so I put it out of scope for this exploration.
The first category is easy, for we already have it. The second category is harder, but once you got past the authentication it’s easy again. One could query a database for visibility = 'authenticated' OR visibility = 'public', that would work.
The third category would require us to keep a list of friends. The fourth category could also require us to keep lists of people, so it might be better to merge them.
Throw in some tables
This brings us to a simple database schema. I see three main tables: entries, people and groups, with a pivot table between all of them: entry_group, entry_person and group_person. I have chosen ‘people’ over ‘users’, because I might not want to give these people write access to anything, but they could be users as well.
It should work like this:
Entries have a field for visibility, which can me marked public, authenticated or private.
People can belong to groups, which have names. Think ‘Friends’, ‘Family’ and ‘Coworkers’.
Entries can be opened up to individual people, or for a whole group.
There might be better ways of naming these, but I like the simplicity of this model. With private posts and audiences, I will always have to manage some form of lists, and this is the most simple way of doing it.
Enter the monster query
So, with some trial and error, PHPUnit tests, and a lot of Laravel magic I came to the following monster query for these tables:
(
select `entries`.*
from `groups`
inner join `group_person`
on `groups`.`id` = `group_person`.`group_id`
inner join `entry_group`
on `groups`.`id` = `entry_group`.`group_id`
inner join `entries`
on `entries`.`id` = `entry_group`.`entry_id`
where `group_person`.`person_id` = ?
)
union
(
select `entries`.*
from `entries`
inner join `entry_person`
on `entries`.`id` = `entry_person`.`entry_id`
where `entry_person`.`person_id` = ?
)
union
(
select *
from `entries`
where `visibility` = 'public'
)
order by `published_at` desc
... which is way shorter when expressed in with Laravel’s Eloquent:
class Person extends Model
{
public function timeline()
{
return $this->groups()
->join('entry_group', 'groups.id', '=', 'entry_group.group_id')
->join('entries', 'entries.id', '=', 'entry_group.entry_id')
->select('entries.*')
->union($this->entries()->select('entries.*'))
->union(Entry::whereVisibility('public'))
->orderBy('published_at', 'desc');
}
public function groups()
{
return $this->belongsToMany(Group::class);
}
public function entries()
{
return $this->belongsToMany(Entry::class);
}
}
Since the method timeline() returns the Query object, other where-clauses can be appended when needed.
I am in a bit of a fight with Laravel still, for it adds
'`group_person`.`person_id` as `pivot_person_id`, `group_person`.`group_id` as `pivot_group_id`' to the first query, which makes it blow up, but the raw query works!
There is possibly a better way of doing it, but this is a start! Feel free to steal or improve, but if you improve, let me know.
Spent a good evening reading up on Reader-discussions and -ideas, then on refactoring the Microsub endpoint in Leesmap into separate Controllers. Very curious how Aaron this does in Aperture (which is also PHP/Laravel), but still not looking at his code until I'm done with it.
Do you know that feeling when you just get out of a rollercoaster and want more, more, more, but when you are being hoisted up in the cart, you're certainly unsure about why again? That's what I feel with IndieWebCamp Berlin right now. But I'm sure it will be fine once I'm there :)
Oh IndieWebCamp. You come with a few things you want to for your own website, then you do some completely other things, and after that you leave with an even longer list of things to do for your own website.
This year is marked as the ‘Year of the Reader’, and indeed, there was a lot of Reader talk last weekend. I really like the progress we are making with Microsub and apps like Indigenous, but I also noticed we’re not there yet for me. But that’s not a discouragement, quite the opposite!
This blogpost has three parts: first I describe the painpoints I feel at the moment, then I describe what I have been hacking on yesterday, and in the last part I share some other ideas we talked about over dinner in Nürnberg, that where not recorded in any form other than short notes on some phones.
Part 1: The current painpoints of the Readers
In May, at IWC Düsseldorf, I installed Aaron’s Aperture (with Watchtower in the back) on my own server, so I could start getting the joys of having my own reader as well. It was before he offered a hosted version, but more on that one later.
So I started using Aperture as a backend, got into Eddie’s beta for Indigenous, tried to make my own frontend, added all my Twitter feeds and got distracted with my dayjob. Although I am using Twitter lists to split up the giant feed into smaller channels per topic, I could not keep up with the volume of it all. When I arrived at Nürnberg Wednesday, I had over 10k of unread posts.
I have a problem with algorithms that sort my posts by parameters I don’t know about, made by people who want to sell my attention to others. I like having an IndieWeb Reader to solve that problem. But I also have a problem with the volume of posts created by people I follow. I want a tool to manage these streams of information, so I probably need a more sophisticated algorithm than just sorting Twitter-users by channel.
As for my 10k unread posts: I declared bankruptcy and marked them all unread to start over. I am glad I wasn’t wasting Aaron’s resources for this.
Speaking of Aaron’s resources: although there are a few other Microsub projects popping up, his Aperture is stil the dominant Microsub-server. He is limiting the services he offers to store posts only for one week to keep people from being too comfortable, but his instance is still slowly growing and there is no ‘competitor’ on the market yet.
As Sven put it: this is another single point of Aaron in our stack.
Those are roughly the points I started my hackday with. I’m not suggesting I have solved them at all, but I tried – as we say in Dutch – to hit multiple flies in one clap.
Part 2: A graph-based IndieWeb-reader
This part gets a bit technical, feel free to scroll ahead to the section about How it looks in the Reader if you’re more into the main idea behind this reader. Also watch the screenshots.
A little while ago I came across the topic of graph-databases and checked out Neo4j. It’s quite a cool tool. I still have very little experience with it, but the basics are not that hard.
The current iteration of this site is written in Kirby and stores posts in .txt files, in a folder structure like 2018/295/13/entry.txt, in which the numbers refer to the year, the day of the year and the number of the post of the day. In order to make things like categories searchable across my 9000+ posts, I index them in an SQLite database. The nice thing about this database, is that I can throw away the contents at any time and just regenerate it from the .txt files.
The original idea I had in mind with the graph database, was to use it as this indexing database. Neo4j can still answer questions like ‘give me all entries with the #indieweb tag’, so I can use it for that. Some posts, however, point to other posts outside of my site. Things like bookmarks and likes have external URLs associated with them, and it would be nice to plot those as a graph. In Nürnberg, however, I realised that it’s cool as an index for my own posts, but even more powerful for an index for a Reader.
Getting it graphed
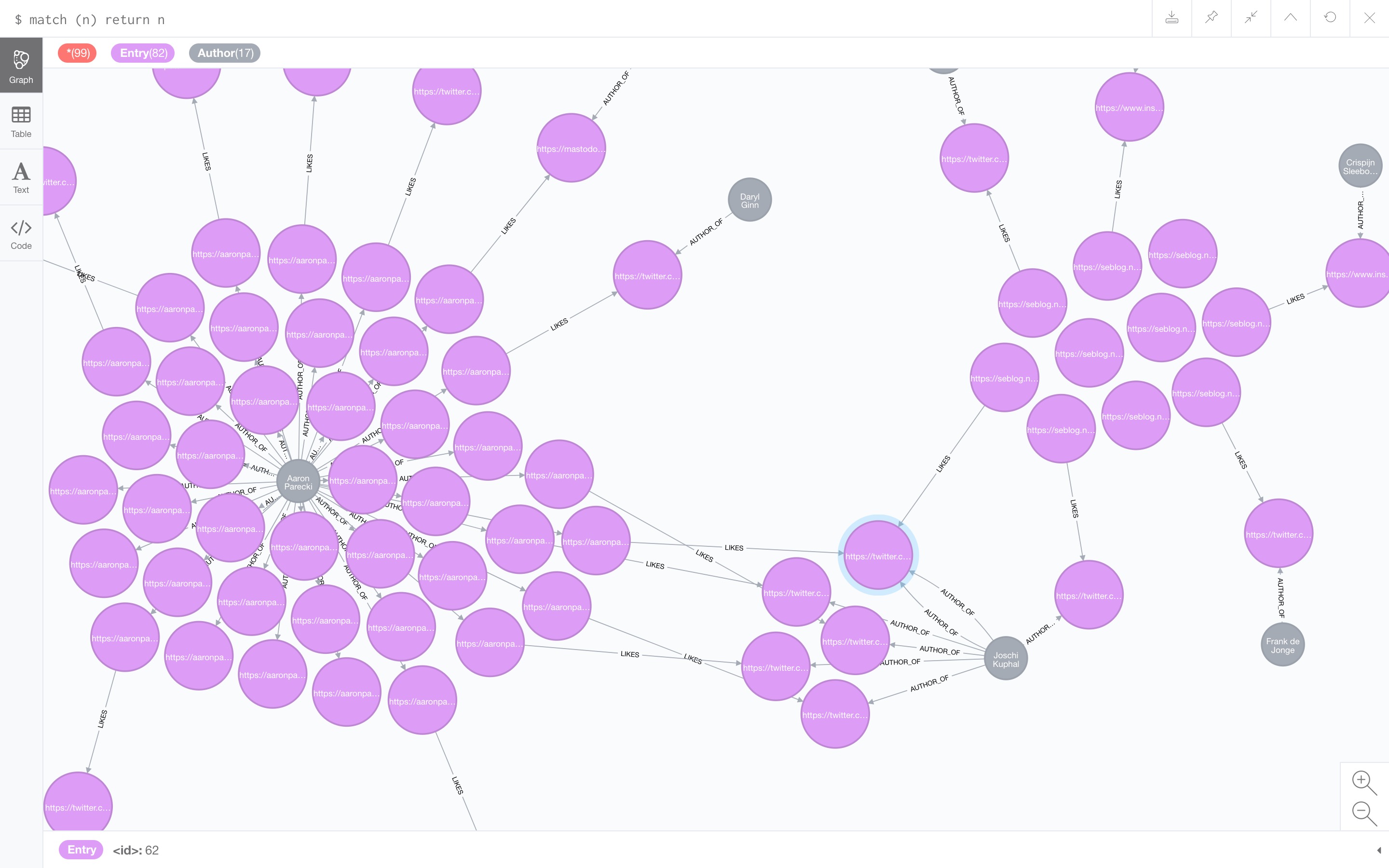
So yesterday I started a Microsub server that does that. It’s really not that far, as I have to manually point it at feeds to import, but it’s a base. Take a look, for example, at the following graph I got after importing Aaron’s main feed, Aaron’s like-feed and my own like-feed:
There is something wrong with my own authorship discovery on feeds, but I placed posts on Seblog near each other. As you can see, there are a lot of posts by Aaron, some of which are likes, which point to other posts (which have authors as well). Aaron likes multiple posts my Joschi. Also note that I like one of those posts too.
The importing algorithm currently looks something like this:
fetch the feed (using XRay);
for every entry, save the entry as an (:Entry) node, storing the full jf2-JSON in a content property, as well as some special properties like published and url for better indexing;
if there is an author:
save the author as an (:Author) node, with name and url properties;
save the relation between these nodes as a -[:AUTHOR_OF]-> relation;
if the entry has a like-of property:
fetch the liked entry;
store the liked entry as another (:Entry) node;
save the relation between the entries as a -[:LIKES]-> relation.
Of course, this can be extended for bookmarks, replies, any mentions really. Note that these relations have a direction, just like a like-post has a direction.
Querying the graph
Looking at the graph provided with Neo4j Desktop is really cool, but it’s not yet a Reader. Luckily that’s not the only output. You can actually query this stuff.
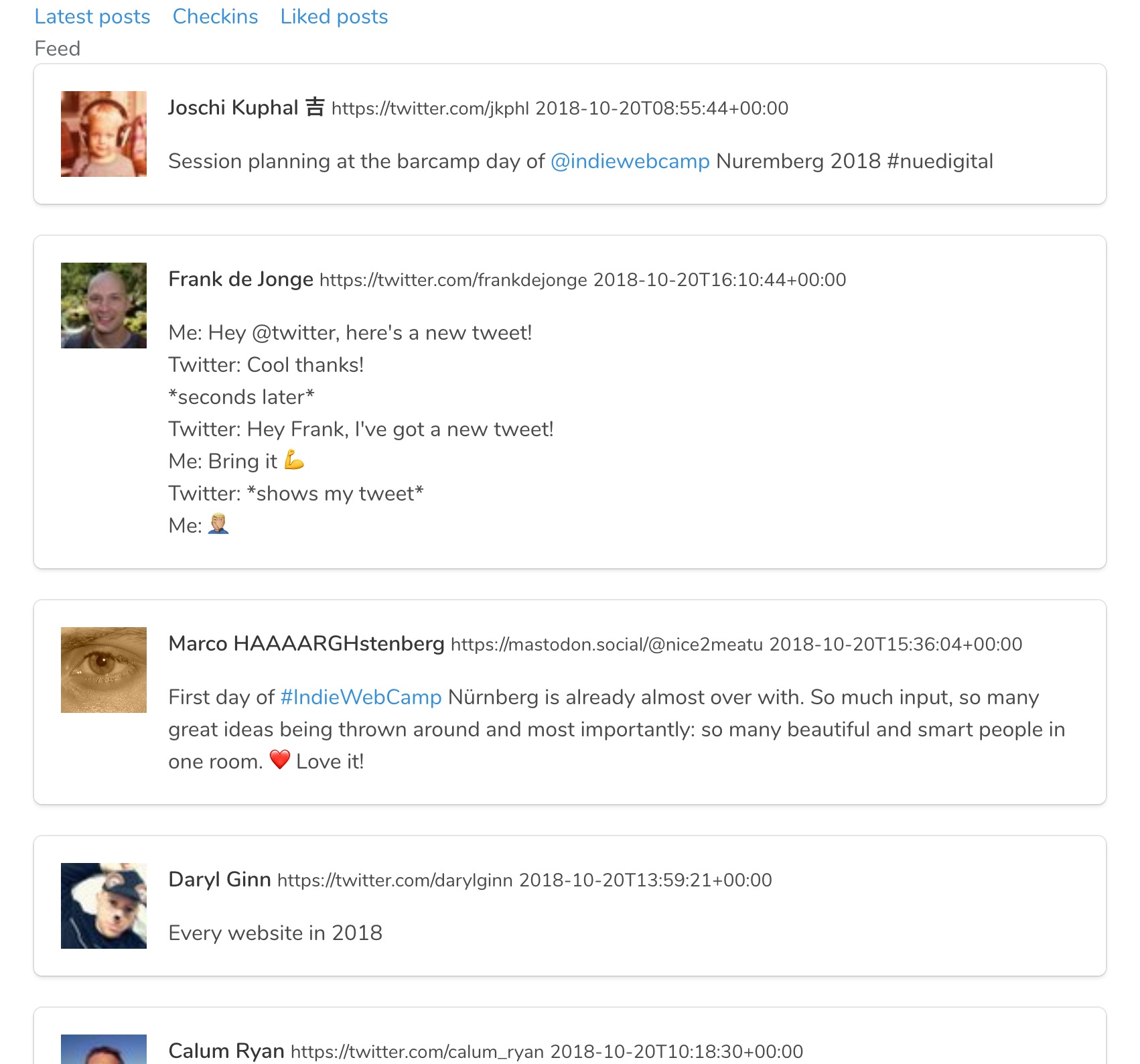
I made a Microsub stub endpoint (without authorization) that could return timelines for three different pre-defined channels: ‘Latest posts’, ‘Checkins’ and ‘Liked posts’. Let me walk you through the queries involved.
In Neo4j’s query language named Cypher, you can form SQL-like statements with a bit of ASCII-art to get your data out. It is made out of two parts: a MATCH and a RETURN. (There are others, like CREATE, but this pair is most useful in this context.)
The query below matches any node ((n)) with the label :Entry, and names those e. It then returns 100 of them, ordered by the published date.
MATCH (e:Entry)
RETURN e
ORDER BY e.published DESC
LIMIT 100
The next query does exactly the same, but filters by the post_type of checkin:
MATCH (e:Entry {post_type: "checkin"})
RETURN e
ORDER BY e.published DESC
LIMIT 100
I believe it’s also possible to create the same query by adding a WHERE e.post_type = "checkin" as a second line, and I have no idea what the difference is. The above example is more ASCII-like, but, it gets even better. Say that we would like to see only posts by Aaron:
MATCH (aaron:Author)-[:AUTHOR_OF]->(e)
WHERE aaron.url = "https://aaronparecki.com/"
RETURN e LIMIT 100
The (n) resembles a node (of any kind, unless specificly tagged), and the -[r]- represents the relation, in our query even in a certain direction.
Now the last query is the most interesting. (Any Neo4j experts out there: please tell me how performant this would be on a bigger data collection.)
MATCH (entry:Entry)-[:LIKES]->(liked:Entry)
WITH liked, count(entry) AS likes
RETURN liked
ORDER BY likes DESC, liked.published DESC
LIMIT 100
This one looks for entries that like other entries. It then counts the number of entries that like these newly discovered liked entries, and orders the result by that.
How it looks in the Reader
If you scroll back to the screenshot of the graph above, you will see that there is one post by Joschi, that is liked by Aaron, that I also liked. This one post is now liked by two people in my graph, and thus it will show up above all other posts.
Here is a screenshot of the result of that query in the reader:
Note that these are all posts that do not appear in any of the feeds I follow in this test-reader: in this reader I only follow Aaron, his likes and my own likes. I have discovered new interesting posts by looking at the likes my friends post.
As a bonus, to take it one step further, I can also actively look for posts of people I do not follow, with something like this (completely untested) query:
MATCH (me {url: "https://seblog.nl/"}),
(entry:Entry)-[:LIKES]->(liked:Entry)<-[:AUTHOR_OF]-
(:Author)<-[:FOLLOWS]-(follower)
WHERE NOT me <> follower
WITH liked, count(entry) AS likes
RETURN liked
ORDER BY likes DESC, liked.published DESC
LIMIT 100
That’s just hard to do in SQL.
I will try to hack on it some more, to get a really functional reader with this graph as a database behind it.
Part 3: Some other strategies worth exploring
So in the previous part, I got kind of carried away with explaining how this graph stuff works. Let me get back to the Reader experience itself. This part consists more of ideas that are not yet implemented by any reader. If you feel inspired, go ahead and make something.
Filtering feed data
In the cocktailbar last night (elitists as we are), we discussed the place of my graph-based Reader (codename Leesmap) next to Aperture. It’s sad that, in order to discover these posts liked by friends, you will need to switch your full Reader backend from Aperture to Leesmap.
We discussed that it would be nice to have an way of using Leesmap with Aperture as a sort of plugin. Leesmap could then receive posts from Aperture, index them, and create a few custom channels to fill with interesting posts.
Any Microsub server could of course use the same mechanism to also have Leesmap plug into it, and others could make filters too, for example spam-filtering or crazy Machine Learning stuff.
We need more thought about how such interaction would look like, but the nice thing is that you can use one server to savely store your data, regardless of the fancy filtering services you choose to use as well.
More ways to combat feed overwhelm
Before IndieWebCamp, we had a discussion about Readers in a traditional Nürnberger restaurant. Here also, people came up with some ideas to deal with accruing unread-counts.
One idea came from how Aperture deletes posts after 7 days. This actually prevents the overload. It would be nice if you can tell your reader that, for example your Twitter feed, is ephemeral and that the posts can be discarded if you did not read them in time.
One other idea that came up was to keep track of the average time between posts of a certain feed. This way a Reader could boost posts when they are from a feed that is not regularly updated. These kind of posts are usually lost in piles of more posts from more frequently updates feeds.
Yet a last idea was to tell your reader to leave out posts with certain words for a small period of time. This can come in handy when you haven’t watched the newest episode of Game of Thrones yet, but want to stay connected to your feeds without spoilers.
This year really is the year of the Reader and it’s really exciting. I will continue to work on Leesmap a bit more, and share progress if I make some. Hope you do too!
Deze blogpost is speciaal voor Frank, die zich op Twitter het volgende afvroeg:
Webmentions blijven tovenarij voor me. @tonzylstra reageert op http://micro.blog op mijn post. Ik reageer daar op zijn verhaal en beiden staan onder de post.
Als dit kan met sociale netwerken... Crossplatform reageren....
Hierbij een poging om Webmentions uit te leggen, niet om de magie ervan weg te nemen, want ik blijf me er zelf ook steeds over verbazen, maar wel om uit te leggen hoe dingen werken.
Waarover we praten als we over Webmentions praten
Het lastige aan de term 'Webmention' is dat verschillende mensen er verschillende dingen onder verstaan. Of liever: de feitelijke Webmention is onzichtbaar, waardoor het zichtbare resultaat al snel ook 'Webmention' gaat heten.
De devs, en dan vooral de spec-lezers (jep, jij, Martijn), verstaan onder de Webmention de interactie tussen twee servers volgens het Webmention-protocol (waarover later meer). De gebruikers, waaronder denk ik ook Frank, bedoelen met 'Webmention' vooral de reacties van andere mensen die automagisch onder je eigen post verschijnen als je een Webmention-plugin installeerd.
Ikzelf vind beide definities acceptabel, maar het is fijn als iedereen op dezelfde pagina zit. Daarom een uiteenzetting.
De Webmention als Ding an sich
Laat ik beginnen met het Webmention-protocol zelf. Dit is een manier om een site op de hoogte te stellen dat er een andere pagina bestaat die naar de site linkt, en waarop informatie te vinden is die mogelijk relevant is. Een voorbeeld.
Stel dat Adriaan en Bassie allebei een blog hebben dat Webmention ondersteunt. Adriaan heeft een stukje geschreven en post deze op zijn blog. Bassie leest dat en heeft er een mening over. Om deze mening te uiten, post Bassie op zijn eigen blog een kattenplaatje, en geeft daarbij aan dat het een antwoord is op Adriaans stukje.
Zodra Bassie het kattenplaatje post, stuurt Bassie's server een notificatie (een POST request) naar Adriaans server, met daarin de link van Bassie's post en Adriaans stukje. Omdat Bassie heeft aangegeven dat het een reactie betreft, staat er een link in zijn stukje een link naar Adriaans stukje. Adriaans server bekijkt de pagina, ziet de link naar de eigen site, en accepteert daarna de Webmention door 'OK' terug te sturen. (Meer precies, een HTTP 200, 201 of 202.)
Met de bovenstaande flow verschijnt er natuurlijk nog niet magisch een reactie op je site. Feitelijk staat daar niets over in het Webmention protocol. Wat gebruikers dus onder 'Webmention' verstaan, is in feitte een extraatje.
Webmention++
In het voorgaande voorbeeld heeft Bassie 'aangegeven' dat zijn stukje een reactie is. Dit aangeven behoort eigenlijk al niet tot Webmention (een gewone link is voldoende), maar kan dus wel nuttig zijn voor de ontvangende partij. Door bijvoorbeeld Microformats toe te voegen aan je website, maak je je website leesbaar voor andere computers en servers. Hieronder een voorbeeld van hoe Bassie's kattenplaatje eruit kan zien in HTML met Microformats:
<div class="h-entry">
<a href="https://adriaan.example/blogpost-over-b300" class="u-in-reply-to">
Voor Adriaantje,
</a>
<img src="/images/lolz/kattenplaatje.jpg" alt="een kattenplaatje" class="u-photo">
van <a href="https://bassie.example" class="u-author h-card">Bassie</a>.
</div>
In dit geval is de Microformats-opmaak vrij specifiek in de boodschap verweven, maar Bassie's blog-software kan deze voor Bassie genereren, indien juist ingesteld. Daar hoeft Bassie dan verder niet meer over na te denken.
Dankzij deze Microformats-opmaak, kan Adriaans server de volgende data uit de pagina halen:
... en die data is voor Adriaans server genoeg om het kattenplaatje weer te geven als reactie!
Wat er daarna met de data gebeurt verschilt per Webmention-implementatie. De meesten slaan het op voor latere weergave. (Het zou niet zo praktisch zijn om bij elk bezoek aan de pagina Microformats te parsen van een X aantal andere sites.) Wie gebruik maakt van een CMS-plugin slaat deze data dus op op de eigen server, Webmention-services zullen de Webmentions op hun server cachen.
Inter-social-mediale webmentions
Tot slot zijn er de reacties op blogs via sociale media. Webmention wordt door sommigen gezien als een magisch protocol waardoor reacties van Twitter op je blog verschijnen. Daar is echter nog wel een extra stap voor nodig: een backfeed-service.
Op dit moment wordt vrijwel alle 'backfeed' van reacties op social media verzorgd door Bridgy. Deze service houdt, als je je aanmeldt, je Twitter, Facebook of Instagram-account in de gaten, op zoek naar reacties, likes en dergelijke en stuurt een Webmention naar de originele post op je website als het er een vindt.
Om dit voor elkaar te krijgen maakt Bridgy een nieuwe pagina aan voor elke like of reactie die het vindt. Op die nieuwe pagina staan de nodige Microformats om aan te geven of het om een like, reactie of anderszins gaat. Daarna stuurt Bridgy een Webmention en treedt de bovenbeschreven flow in werking. Het idee is dat Bridgy op deze manier de taak overneemt tot Twitter, Facebook en Instagram zelf Webmentions gaan sturen.
Webmentions, dus
Het is dus geen magie, al blijft het wel magisch voelen. Ikzelf vind nog steeds een 'indie-Webmention', een webmention tussen twee sites zonder tussenkomst van derden, een van de gaafste dingen die er is. Maar uiteindelijk is een Webmention dus niet meer dan een link van post A naar post B, een POST-request en wat markup die vertelt waar post B nou eigenlijk over gaat. En een brouwseltje van kikker, kamperfoelie en haarlak, tweemaaldaags na de maaltijd.
In het verhoor riep Zuckerberg dat onze data van ons was en dat we het zo konden downloaden. Die download is meer om mensen tevreden te houden, bevat platgeslagen html – nog net geen pdf – en dus lastig te verwerken of exporteren, mocht je zelf nog iets anders met je data willen.
At Virtual HWC last week, Sven Knebel pointed me to the new Firefox beta. I use it now, and one of the things I noticed is that ships with integration with Pocket, a bookmarking service to save articles you want to read later. It’s owned by Mozilla now, so they accentuate their service by adding a button prominently in your address bar.
Despite the pushiness, I tested it out a bit. I like that I can save articles with one click, so I can read them later, possibly on a different device. It made me think about the way I post bookmarks on my own site.
My bookmarks and likes look too similar
The way I have implemented bookmarks at this moment, is very, very similar to the way I implemented likes. It is a Microformats property (u-bookmark-of vs u-like-of), displayed as an icon (a grey bookmark vs a red heart), with a Dutch text (‘Seb heeft [dit] gebookmarkt.’ vs ‘Seb vindt [dit] leuk.’).
By making bookmarks and likes this similar, one would almost think that there is a clearly defined difference in the words ‘bookmark’ and ‘like’, that keep them apart, since there is no other distinction. I don’t think there is such a definition.
Bookmarks are mostly used as a ‘want to read’-list, or a way of keeping track of things that have been read, but might be of interest on a later moment (‘want to read again’). Likes are more a reply of some sorts, directed at the author of the post, expressing appreciation.
The problem comes when I take readers of my blog into account. The things I like, might be read as a recommendation, but the things I bookmark, might also read as a recommendation. Once I start looking from that perspective, likes and bookmarks fulfill the same role again.
When likes and bookmarks are not recommendations
Sometimes I like things on social media, not because of the contents of the post, but because of the social context around the post. I do not really like the bad picture of the malformed pizza of a friend, I like the fact that I recognize that pizza as the outcome of the enthusiastic plans about making a pizza that my friend told me about earlier that day. I sometimes don’t like the specific check-in a person posted, I just like the person. Some tweets are also quite ambigu: do I like the tweet because of the tweet, or because of the linked article I might or might not have read?
Those likes are not recommendations for readers, they are purely appreciation, or even just social acknowledgement. Within a certain social context they can be of value to other people, but to random strangers, they are not. Currently, I solve this problem by not posting those kinds of likes to my site at all (leaving them on Facebook or whatever silo), but that’s of course not ideal in the IndieWeb scheme of things.
With bookmarks, a similar thing can happen: not all bookmarks are recommendations. The easiest example is an article that I think looks interesting, so I bookmark it to read it later, but I haven’t read it yet. I do not recommend that article, but a reader might think that.
In both cases: sometimes I do want to recommend an article in a single post.
What I don’t want to propose
Let me make a little pause here and say something about likes, favorites, recommendations and what more. We can solve the above things by just adding more webactions to the field. “Let’s also support, next to bookmarks and likes, favorites and recommendations.” But I don’t think that’s the solution, because adding those options means just more post types to keep track of, for both publishing sites and consuming indie-readers.
Keeping things a little bit abstract and minimal helps us focus on the problem at hand. (Which is at this moment, I think, building an functioning indie-reader in the first place.)
What I would add to my bookmarks
Seeing what Pocket does with bookmarks, I think I want to expand what I post as a bookmark. To be fair: a lot of other people on the IndieWeb have more detailed bookmarks too. Other properties of a bookmark include: tags, a little summary of the bookmarked post, the reason why the post was bookmarked and sometimes even a screenshot of the bookmarked page.
I’m not sure how much I want to add to them, but since they are very skinny now, I certainly would like to add some tags. Tags, and possible a reason, make it easier to find a bookmarked article back after a while.
That brings me to what I think a bookmark would be for me: showing an interest in the linked article, without adding too much judgement. I see bookmarks as a personal archive of things I want to read or have read. If technical skills allow it, I would also save a copy of the post for personal use, hidden in the bookmark-post itself.
What I would change to likes
To likes I wouldn’t change much. For likes, I want to make a personal copy of the original too, because I do care about that content, but from the outside, it’s just a link.
But the value of the like would than be more of a vote: this is a piece of content I care about. I think indie-readers should also consume those likes, but just don’t display them the way they display a photo or a note. If there is a post by an author that I don’t follow, but that is liked by, say, three people I do follow, then I want to see that post, accompanied by the names of the three people who liked it.
The threshold for the external posts to show up may vary from person to person, both personal preferences of the reader as well as the status of the poster of the like. But the point is that it’s a indie-reader-problem.
In this way, a like is in fact a recommendation, from the readers perspective, but just appreciation from the poster.
But back to these social likes
Then there are still those likes that depend on some social context, that aren’t solved by the above approaches.
I think that the root of the problem lies in those exact words: social context. If I like a certain badly photographed pizza, I should not post that to my main feed, but set the visibility of that like to ‘friends only’. Chances are that the badly photographed pizza was already published as a private post, only visible to a certain audience, so I can copy that.
The problem here lies more in an easy way of publishing private posts, and an easy way to change the audience of those posts. And of course a way for sites to securely share those posts with the right indie-readers, there is a long way to go still.
And what about the bookmarks you haven’t read?
Sharing unread bookmarks is also, I think, question of adding the right audience to the post. Such bookmarks can be posted with an ‘only me’ visibility. You can then subscribe your indie-reader to your own (private and public) bookmarks-feed. This is, without the private part, what I actually did for a while when I was using an indie-reader. Apart from the bugs in my self-build reader, it worked very well.
And really recommending something? Well, if I really want to recommend something to people who follow me, I can always just post a note, linking the article, and explain why they should read it. That also improves the chance of actually clicking through, no need for extra formatting.
Conclusion
In the end I don’t think we need better boundaries between a bookmark and a like, in the form of extra ‘recommend’ or ‘favorite’ webactions. A bookmark adds something to an archive for yourself, and a like is giving appreciation to the creator of the post. Recommendations can be either explicit by posting a note, or implicit by publicly liking or bookmarking. But, the way this is implied should be the responsibility of your indie-reader, where you can mix to your own taste. Publishers could filter things that they don’t want everybody to pick up as recommendations by using ‘only friends’, ‘only who I follow’ or ‘only me’ posts.
In the end of the day, this is a lot of thinking and talking. I should get back to creating a indie-reader. As should you, because that’s where the one of the undefined parts of the IndieWeb lies now.
In last weeks IndieWeb newsletter I read a blogpost by Sven about having notifications for webmentions and such via IRC. He described more or less the setup I have too: using Aaron’s TikTokBot framework, running on the same machine as a private IRC server for it and your IRC bouncer. In my case, the machine is a Raspberry Pi in my living room, but Sven’s guide describes more or less what I did too, so please check that out.
I divided my webmention notifications into webmentions and silomentions (that’s backfeed from services like Bridgy and OwnYourSwarm) and I also get notifications for logins and Micropub requests, so I can keep track of what’s happening on my blog. But that’s just expanding the notifications. I added some other functionality I wanted to talk about.
Hey bot, please like this post
The one thing that made me post on my site the most, was adding Micropub support. There are various Micropub clients out there that you can use to just write a blogpost, to post a like, to import checkins from Swarm or what have you. But since it’s so simple (once you know how), I also made a lot of Micropub clients out of Workflow, Paw or, in this case, my IRC bot called Bop.
I can now say like https://example.com/a-post in the same channel my notifications come in, and Bop will post a like-post on my site. My site will then post the webmention and if the other site accepts it, it will be shown as a like under the post, just like that.
Please refer to Sven’s blogpost to learn how to set the bot up. I also assume you already have a site that supports Micropub. I will go into obtaining an access token a bit, but that might be a tricky part and depends on how your Micropub endpoint works.
Getting your bot hooked
Sven mentions the file ‘hooks.yml’, which contains hooks: [] for him. The hooks-file defines the things the bot will respond to, and since Sven only want to receive notifications, not talk to his bot, he does not need hooks. But we do. Replace the contents of the hooks file with the following:
As you can see, I like to match for a URL to support like, bookmark and rsvp, and for anything to support notes on your own site, Twitter and Facebook. Feel free to change the syntax to your own needs.
Under channels, I defined @seblog, which means ‘every channel in the server seblog’. That name comes from your config.yml, and it’s a safety measure, so that when I connect my bot to Freenode also, it won’t accept likes from other people. I am the only person connected to the private IRC network Seblog, so that will be fine.
Creating the Micropub.php
As you saw, the hooks define a URL that will be called by the bot. I specified that to be on localhost:8000 and point to micropub.php. In your TikTokBot folder (or where you want, really) create a folder called ‘server’ and a file within it called ‘micropub.php’. Let’s start with the following to test it out:
<?php
header('Content-Type: application/json');
echo json_encode([
'content' => 'Hi, you called for a Micropub?'
]);
Then go to the newly created folder and run the command php -S localhost:8000. This starts up a webserver from that folder, so if you now go to your private channel and say note This is a test, you will see that the bot responds. If you say something that does not match the regex, the bot will stay silent.
Give me my data back
If we want to send data to our Micropub endpoint, we need to make sure that our bot has that data. Let’s make the bot echo whatever we said, so we know that he heard us.
TikTokBot gives us a JSON object of the message via the POST data. Long story short, you can get it by using the following:
<?php
header('Content-Type: application/json');
$message = json_decode(file_get_contents("php://input"));
$full = $message->content;
$action = $message->match[0];
$param = $message->match[1];
echo json_encode([
'content' => "Hi, you said '$full', you wanted to $action $param?"
]);
Now, if you say like https://seblog.nl/2017/08/19/6/micropub-irc-bot, the bot will respond with Hi, you said 'like https://seblog.nl/2017/08/19/6/micropub-irc-bot', you wanted to like https://seblog.nl/2017/08/19/6/micropub-irc-bot?. Try it out, and different actions too, so you know it works!
Make sure not to echo the full message, because since the bot listens to itself, that message will trigger itself again, resulting in the bot repeating the message over and over again. (Just restart the bot if that happens.)
Sending a POST request
A Micropub request is, in the end, just a POST request. Here’s a little helper function to send one for you. Just start with this code at the top of your file, right after <?php.
Make sure to replace that URL with your own Micropub endpoint, and xxx with your own access token. I’ll talk about obtaining one at the bottom of this post.
I don’t have the bot say anything after this, because the bot will give a notification once a Micropub request is made, which is enough feedback for me. You could also return whatever send_post() returns, I leave that up to you.
More post types
As you can see in the code above, you can just add fields to the array. Here are some other elseifs I use.
See how easy that is? Please make up new ones and tell me about it!
I’m particularly proud of the tweet one, which will, thanks to the exit(), not post the tweet unless it fits the 140-chars-rule.
Please note that the use of the syndicate-to fields (or the newer mp-syndicate-to) depend on your own website. This only gives my webserver the order to syndicate, it does not syndicate by itself. If your server does not know how to syndicate to Twitter, it will not work, but explaining how to do that is it’s own tutorial.
In real life, I actually have note set to 'private' => true and 'audience' => 'http://seblog.nl/, so it’s a private note. But: 1) I don’t expect many people to support private posts, 2) how many people are interested in posting things to their website only they themselves can see? and 3) I want to change the 'private' => true to 'visibility' => 'private', or something like that.
That’s it!
There you go, a customisable Micropub chatbot. Please double check that it’s only doing it’s thing on your private IRC server, and not on any public servers where your bot might lurk (if you use any). Have fun liking and posting!
POST-scriptum: Obtaining an access token
The question “what do I replace ‘xxx’ with?” is a hard one to answer, because it totally depends on how your site handles access tokens. Most Micropub clients ship with an IndieAuth flow to obtaining one, but since we’re making this one ourselves, we have to get one manually.
You can do this by following the steps on the wiki, if you have a way to send POST requests. You can also log in to a Micropub client like Quill, which shows you the access token it got, and use that. Since this all depends on your own site, it might offer an easier way, or it might not.
Update 2017-10-04: In an earlier version of this post, I did not set a Content-Type: application/json-header, so the bot didn't actually respond. Setting that header at the top of your file will fix that.
Sad to hear, especially since you tried to use my plugins. But I will not try to convince you to come back, I know my plugins are lacking. They are just pieces of my own site I open sourced, but the way I cut them off might break things.
I am actively working on two new ones at the moment, with some 'official' IndieWeb libraries, with unit testing, hopefully even with panel widgets. They should be much more stable and user friendly than the old ones.
So I am not asking to come back now, but please, let me ping you when I got the new ones ready. I hope you will like those.
We're a long way from general adoption, but we can make steps.
Oh hey, you're right, my webmention plugin does not pass most of the tests out of the box! I was trying to get some of the code into the Toolkit, but it seems like they are too busy with Kirby 3 and don't care about my function. I should move my code into the plugin so that it passes all but one test again.
I’ve been following the #indieweb channel on IRC for a while now, sometimes more active than other times, and my several methods. In the beginning, I just read the logs on chat.indieweb.org, but when I wanted to say something I had to login with Textual.
Back in Amsterdam I had a bad internet connection (they probably tried to block IRC) so I wasn’t using it a lot. Then there was the bridged Slack channel, which I used intil my first HWC, where Martijn introduced me to thelounge. I installed it on a Raspberry Pi I had lying around and used that for quite a while, until I became inactive and shut the thing down.
Unfortunately I haven’t been able to make it work again after that, so I was in need of something else. Meanwhile I got used to Textual again, and I kind of liked that, except that it disconnected every time my laptop went to sleep.
Ok, so, ZNC you said?
Yeah, enough history! Let’s get to it. ZNC is an IRC bouncer, which connects to IRC for you. When you connect to ZNC, ZNC will give you all the messages it received since you where away. So accedentally closing your laptop? No worries, just open it and you receive all messages again.
You still need some computer to be online all the time, but I had that same Raspberry Pi (first edition model B), and it’s perfect for this job.
I first followed the installation instructions here, first downloading the latest source tarball, and following the unpacking and configuring described on that page. Later on, I had to use a different flag on configure, so I added that one here for you. I used the following commands in order:
wget https://znc.in/releases/znc-1.6.5.tar.gz
tar -xzvf znc-1.6.5.tar.gz
cd znc-1.6.5
./configure --enable-python
make
sudo make install
This all takes a while, especially the make part.
I then made sure I opened a port on my router towards my RPi, so I could access it from outside my home-network, when I’m on the go (look for the NAT settings in your router).
Extra modules
Then for extra modules. The webadmin was on, so I could just go to my home-IP + my new port, let’s say https://192.0.2.0:8000. I had SSL enabled and bad certificates, so you might need to trick your browser into accepting them. In the global modules, I enabled chansaver, lastseen and log. I also had notify_connect, but it felt too noisy for me. Don’t forget to hit the ‘save’ button.
In ‘Your Settings’ I have chansaver and controlpanel on, I believe by default.
For other module configuration I connected to ZNC using Textual. When you add it, you can give it a connection name (this is for yourself). The server address is your home IP, and the port the outside port you put in your router. The server password is the one you put in ZNC in the ./configure step. But then comes the part where I was puzzled: go from the ‘General’ to the ‘Identity’ view, and add your Freenode IRC nickname as ‘Nickname’, but your ZNC username as Username. I used sebsel@Mac/freenode, to identify it later. The personal password is for the NickServ password on Freenode.
After connecting I did /msg *simple_away SetTimer 0, because I want to be set to away the moment all my devices are disconnected from ZNC.
Because I want to have Textual on my Mac, and this new-found Mutter on my iPhone, I have to get ZNC to manage multiple clients. By default, ZNC sees you have read your messages on your iPhone, so it does not send it to your Mac. To keep track of multiple clients, you need the ClientBuffer module.
Since I still had the source, I could just compile the module. So I did:
cd ~/znc-1.6.5/modules/
wget https://github.com/jpnurmi/znc-clientbuffer/blob/master/clientbuffer.cpp
cd ~/znc-1.6.5/
make
sudo make install
After that, I got back to Textual, and did /msg *status LoadMod clientbuffer. After that, you can /msg *clientbuffer help and send *clientbuffer some commands as messages. I did AddClient Mac and AddClient iPhone. You can do a ListClients too to see what you got.
Adding Mutter to the game
On the iPhone app Mutter, I added a network with again my home IP as the server, my nickname sebsel and under Advanced use the port I opened, added the password of ZNC in the first password field. The ‘username’ under Advanced gets the username for ZNC, so I made it sebsel@iPhone/freenode, to let Clientbuffer identify it as my iPhone. If you have notify_connect on you will see that *status notifies you about logging in with your iPhone.
Warning: I didn’t get this next part to work
Next I saw that there is an option to receive notifications from ZNC to your iPhone via Mutter. You will need their mutter-push module for that, and that requires ModPython, so that’s why I added the flag --enable-python during the first make.
As their explanation says, first grab the mutter package, then make sure you got the right python libs, and then move mutter.py to ~/.znc/modules/.
cd ~
wget https://bitbucket.org/jmclough/mutter-push/get/master.zip
unzip -d mutter -j master.zip
cd mutter
sudo apt-get install python3-pip
sudo pip3 install requests
cp mutter.py ~/.znc/modules/
In IRC, make sure to /znc loadmod modpython and then /znc loadmod mutter (or send a message to *status with loadmod modpython etc.).
This last part of getting notifications is still not working for me. I still wanted to post this though, because all the other things work. Hope I’ll get back to notifications soon, when I do get them to work.
This weekend I worked on some things on Seblog, and since I did some productive work on other projects today, I feel like I can write a blogpost about it without sounding so procrastinating.
Inspired by Aaron Parecki's monthly overviews, and triggered by @zegnat, who was looking for the same type of page on my site, I started to 'deconstruct' my URLs. You can now remove parts of it and still get useful pages. That was on my list of itches since november 2015 now.
So let me explain my URL design first. This post, for example, is /2017/06/20/1/daily-and-monthly-overviews. This is an idea I got from the wiki, and probably also originates with Aaron. The identifying part of it is the date, followed by an ID (the nth post of that day). The slug is just for humans and can be omitted: you will get redirected to the right one. Some posts don't even have one. This allows for a Whistle-style URL shortener which I run at 5eb.nl. (This post can be found through 5eb.nl/4ox1.)
The first step was to remove the ID, to get to a day view. I just list all the posts that are created on that day, including private posts when I'm logged in, but oldest-first instead of the newest-first order of my feeds. I also display a summary of the day in icons at the top. I'm really pleased with how it turned out!
After that, I also wanted the monthly view, to get a better overview. I'm really pleased with that too, it's nice to go through my old posts this way, seeing old memories. I'm now more interested in importing my Facebook posts too. I am still looking for a way to have some anchor or summary of the day in my monthly view, to find posts quicker, and adding a location like Aaron might do the trick, but I'll have to figure out how to do that still :)
The past week I mentioned both Martijn and the Twitter-account of the Dutch Railways (@ns_online) in different blogposts. For Martijn, I used a hand-written link with the proper .u-category.h-card classes to person-tag him. [see update below] For @NS_online, I wanted to @-mention them in the POSSE'd tweet. Martijn complained that my blog didn't autolink them, so that's what I fixed now.
I have a new syntax to @-mention (and thus tag) people in my blogposts.
I want to match names like @name
I don't want to match the word @-mention itself.
I want to be able to escape the @-mention with a \, like \@name, so I can talk about @-mentions in a blogposts (this one, actually, I like meta-meta-meta).
Then the syntax. Obviously I use an @-symbol, with a name behind it. I then check the name for the following:
Is the name on my list of names? Then use the URL I provided.
Does the name contain a dot? Then assume it's a domain / URL itself, so add replace @ with http:// (@seblog.nl becomes <a href="https://seblog.nl/">Sebastiaan Andeweg</a>)
And if it doesn't contain a dot, assume it's a Twitter account.
I then fetch the h-card (or profile information) from the resulting URL, and use the name that's there.
There are times, however, where I want to specify the name. In the example at the beginning of this post, I called Martijn 'Martijn', not 'Martijn van der Ven', which is on is h-card. Sometimes a full name makes no sense. So I can add the name I want to use in brackets behind the tag (@Zegnat[Martijn]). This way I have total control over my text (and possible conjugations if I start writing in a language that needs those, not that I speak one).
Then it all comes down to the following syntax:
@namefromcache > the URL I specified
@someone.com > that URL
@facebook.com/someone > also the literal URL
@twitteruser > their Twitter profile URL
@someone[This Person] > my own name for them
\@someone > escaped tag
I now need to redo my automated webmention-sending, for it does not yet recognise these tags. Manual sending works fine!
Edit: after some discussion during the Virtual HWC EU-time, I realised that just doing @someone is not really person-tagging them. Person tagging is explicitly saying "I am now with this person", which makes sense for photos and checkins, but not always in blogposts.
I added a minor tweak: I can now use + instead of @ to really person-tag someone. The @ is used for just a mention, the +-mention will receive the class="u-category h-card" markup. I don't know how much I will be using that, but I have that option now.

 Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
Facebook