Nice! Ik deed dit inderdaad ook een tijdje: checkins kwamen niet voor in mijn feed, evenals antwoorden zoals deze. Antwoorden staan er nog steeds niet in, maar sinds ik mijn checkins achter een login heb geplaatst, staan de paar die ik wel publiek weergeef gewoon in de hoofdfeed.
Daarnaast heb ik verschillende pagina's voor likes, bookmarks, replies, etc., en je kan ze allemaal afzonderlijk volgen. Ik heb zelfs een aparte feed voor Engelse posts. En dat bracht me op het idee: misschien moet ik een pagina maken op mijn weblog, waar iemand zelf een feed kan samenstellen. Gewoon, een formuliertje waar je kan zeggen: dit wel, dat niet. En dat formulier berekent dan een URL waarop precies die content met die filters staat.
Want het is natuurlijk leuk als RSS-feeds kunnen filteren tussen wat ik publiceer, maar het is efficiënter voor ons beiden als ik je geen posts stuur die je sowieso niet wil zien.
Oh IndieWebCamp. You come with a few things you want to for your own website, then you do some completely other things, and after that you leave with an even longer list of things to do for your own website.
This year is marked as the ‘Year of the Reader’, and indeed, there was a lot of Reader talk last weekend. I really like the progress we are making with Microsub and apps like Indigenous, but I also noticed we’re not there yet for me. But that’s not a discouragement, quite the opposite!
This blogpost has three parts: first I describe the painpoints I feel at the moment, then I describe what I have been hacking on yesterday, and in the last part I share some other ideas we talked about over dinner in Nürnberg, that where not recorded in any form other than short notes on some phones.
Part 1: The current painpoints of the Readers
In May, at IWC Düsseldorf, I installed Aaron’s Aperture (with Watchtower in the back) on my own server, so I could start getting the joys of having my own reader as well. It was before he offered a hosted version, but more on that one later.
So I started using Aperture as a backend, got into Eddie’s beta for Indigenous, tried to make my own frontend, added all my Twitter feeds and got distracted with my dayjob. Although I am using Twitter lists to split up the giant feed into smaller channels per topic, I could not keep up with the volume of it all. When I arrived at Nürnberg Wednesday, I had over 10k of unread posts.
I have a problem with algorithms that sort my posts by parameters I don’t know about, made by people who want to sell my attention to others. I like having an IndieWeb Reader to solve that problem. But I also have a problem with the volume of posts created by people I follow. I want a tool to manage these streams of information, so I probably need a more sophisticated algorithm than just sorting Twitter-users by channel.
As for my 10k unread posts: I declared bankruptcy and marked them all unread to start over. I am glad I wasn’t wasting Aaron’s resources for this.
Speaking of Aaron’s resources: although there are a few other Microsub projects popping up, his Aperture is stil the dominant Microsub-server. He is limiting the services he offers to store posts only for one week to keep people from being too comfortable, but his instance is still slowly growing and there is no ‘competitor’ on the market yet.
As Sven put it: this is another single point of Aaron in our stack.
Those are roughly the points I started my hackday with. I’m not suggesting I have solved them at all, but I tried – as we say in Dutch – to hit multiple flies in one clap.
Part 2: A graph-based IndieWeb-reader
This part gets a bit technical, feel free to scroll ahead to the section about How it looks in the Reader if you’re more into the main idea behind this reader. Also watch the screenshots.
A little while ago I came across the topic of graph-databases and checked out Neo4j. It’s quite a cool tool. I still have very little experience with it, but the basics are not that hard.
The current iteration of this site is written in Kirby and stores posts in .txt files, in a folder structure like 2018/295/13/entry.txt, in which the numbers refer to the year, the day of the year and the number of the post of the day. In order to make things like categories searchable across my 9000+ posts, I index them in an SQLite database. The nice thing about this database, is that I can throw away the contents at any time and just regenerate it from the .txt files.
The original idea I had in mind with the graph database, was to use it as this indexing database. Neo4j can still answer questions like ‘give me all entries with the #indieweb tag’, so I can use it for that. Some posts, however, point to other posts outside of my site. Things like bookmarks and likes have external URLs associated with them, and it would be nice to plot those as a graph. In Nürnberg, however, I realised that it’s cool as an index for my own posts, but even more powerful for an index for a Reader.
Getting it graphed
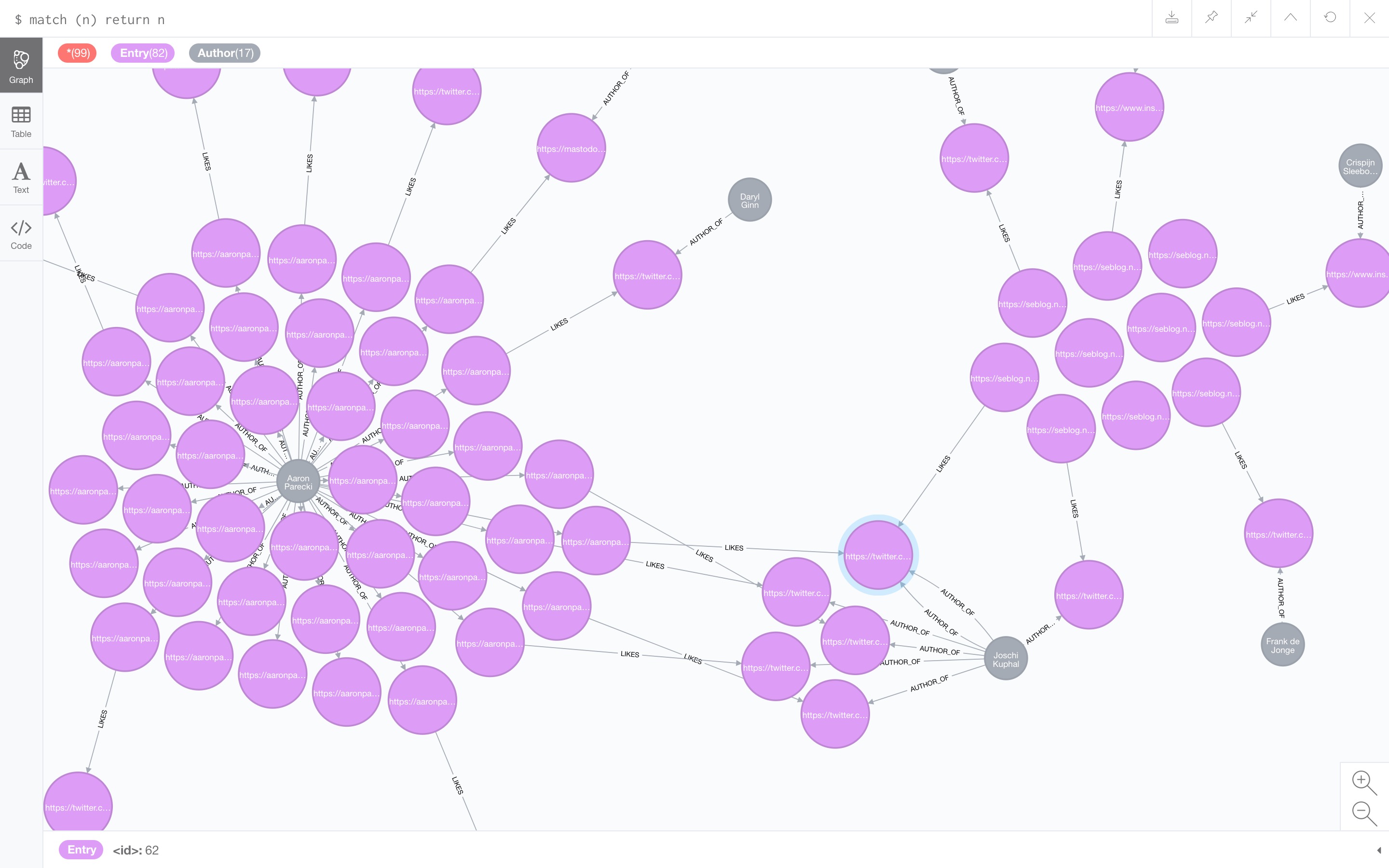
So yesterday I started a Microsub server that does that. It’s really not that far, as I have to manually point it at feeds to import, but it’s a base. Take a look, for example, at the following graph I got after importing Aaron’s main feed, Aaron’s like-feed and my own like-feed:
There is something wrong with my own authorship discovery on feeds, but I placed posts on Seblog near each other. As you can see, there are a lot of posts by Aaron, some of which are likes, which point to other posts (which have authors as well). Aaron likes multiple posts my Joschi. Also note that I like one of those posts too.
The importing algorithm currently looks something like this:
fetch the feed (using XRay);
for every entry, save the entry as an (:Entry) node, storing the full jf2-JSON in a content property, as well as some special properties like published and url for better indexing;
if there is an author:
save the author as an (:Author) node, with name and url properties;
save the relation between these nodes as a -[:AUTHOR_OF]-> relation;
if the entry has a like-of property:
fetch the liked entry;
store the liked entry as another (:Entry) node;
save the relation between the entries as a -[:LIKES]-> relation.
Of course, this can be extended for bookmarks, replies, any mentions really. Note that these relations have a direction, just like a like-post has a direction.
Querying the graph
Looking at the graph provided with Neo4j Desktop is really cool, but it’s not yet a Reader. Luckily that’s not the only output. You can actually query this stuff.
I made a Microsub stub endpoint (without authorization) that could return timelines for three different pre-defined channels: ‘Latest posts’, ‘Checkins’ and ‘Liked posts’. Let me walk you through the queries involved.
In Neo4j’s query language named Cypher, you can form SQL-like statements with a bit of ASCII-art to get your data out. It is made out of two parts: a MATCH and a RETURN. (There are others, like CREATE, but this pair is most useful in this context.)
The query below matches any node ((n)) with the label :Entry, and names those e. It then returns 100 of them, ordered by the published date.
MATCH (e:Entry)
RETURN e
ORDER BY e.published DESC
LIMIT 100
The next query does exactly the same, but filters by the post_type of checkin:
MATCH (e:Entry {post_type: "checkin"})
RETURN e
ORDER BY e.published DESC
LIMIT 100
I believe it’s also possible to create the same query by adding a WHERE e.post_type = "checkin" as a second line, and I have no idea what the difference is. The above example is more ASCII-like, but, it gets even better. Say that we would like to see only posts by Aaron:
MATCH (aaron:Author)-[:AUTHOR_OF]->(e)
WHERE aaron.url = "https://aaronparecki.com/"
RETURN e LIMIT 100
The (n) resembles a node (of any kind, unless specificly tagged), and the -[r]- represents the relation, in our query even in a certain direction.
Now the last query is the most interesting. (Any Neo4j experts out there: please tell me how performant this would be on a bigger data collection.)
MATCH (entry:Entry)-[:LIKES]->(liked:Entry)
WITH liked, count(entry) AS likes
RETURN liked
ORDER BY likes DESC, liked.published DESC
LIMIT 100
This one looks for entries that like other entries. It then counts the number of entries that like these newly discovered liked entries, and orders the result by that.
How it looks in the Reader
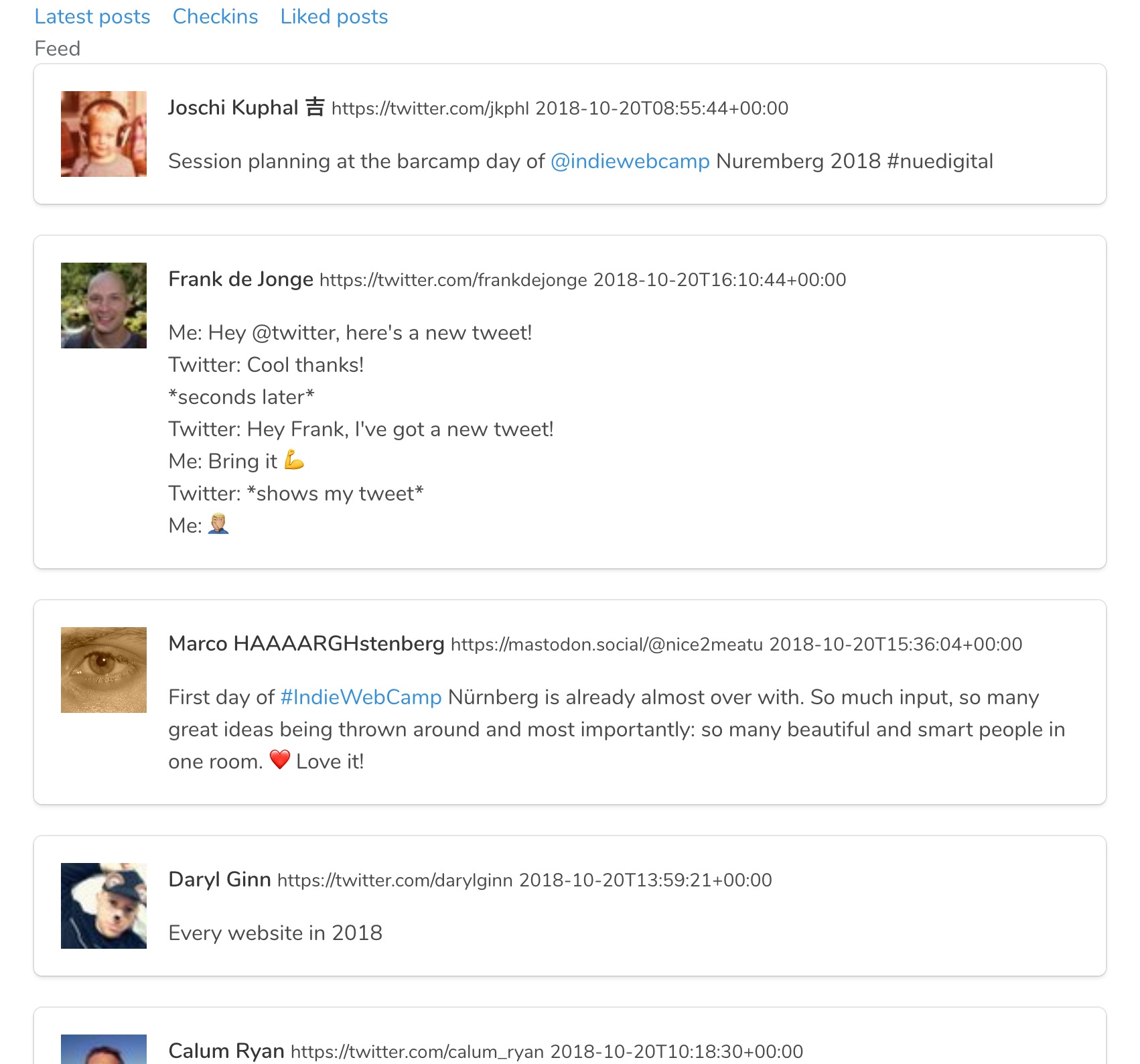
If you scroll back to the screenshot of the graph above, you will see that there is one post by Joschi, that is liked by Aaron, that I also liked. This one post is now liked by two people in my graph, and thus it will show up above all other posts.
Here is a screenshot of the result of that query in the reader:
Note that these are all posts that do not appear in any of the feeds I follow in this test-reader: in this reader I only follow Aaron, his likes and my own likes. I have discovered new interesting posts by looking at the likes my friends post.
As a bonus, to take it one step further, I can also actively look for posts of people I do not follow, with something like this (completely untested) query:
MATCH (me {url: "https://seblog.nl/"}),
(entry:Entry)-[:LIKES]->(liked:Entry)<-[:AUTHOR_OF]-
(:Author)<-[:FOLLOWS]-(follower)
WHERE NOT me <> follower
WITH liked, count(entry) AS likes
RETURN liked
ORDER BY likes DESC, liked.published DESC
LIMIT 100
That’s just hard to do in SQL.
I will try to hack on it some more, to get a really functional reader with this graph as a database behind it.
Part 3: Some other strategies worth exploring
So in the previous part, I got kind of carried away with explaining how this graph stuff works. Let me get back to the Reader experience itself. This part consists more of ideas that are not yet implemented by any reader. If you feel inspired, go ahead and make something.
Filtering feed data
In the cocktailbar last night (elitists as we are), we discussed the place of my graph-based Reader (codename Leesmap) next to Aperture. It’s sad that, in order to discover these posts liked by friends, you will need to switch your full Reader backend from Aperture to Leesmap.
We discussed that it would be nice to have an way of using Leesmap with Aperture as a sort of plugin. Leesmap could then receive posts from Aperture, index them, and create a few custom channels to fill with interesting posts.
Any Microsub server could of course use the same mechanism to also have Leesmap plug into it, and others could make filters too, for example spam-filtering or crazy Machine Learning stuff.
We need more thought about how such interaction would look like, but the nice thing is that you can use one server to savely store your data, regardless of the fancy filtering services you choose to use as well.
More ways to combat feed overwhelm
Before IndieWebCamp, we had a discussion about Readers in a traditional Nürnberger restaurant. Here also, people came up with some ideas to deal with accruing unread-counts.
One idea came from how Aperture deletes posts after 7 days. This actually prevents the overload. It would be nice if you can tell your reader that, for example your Twitter feed, is ephemeral and that the posts can be discarded if you did not read them in time.
One other idea that came up was to keep track of the average time between posts of a certain feed. This way a Reader could boost posts when they are from a feed that is not regularly updated. These kind of posts are usually lost in piles of more posts from more frequently updates feeds.
Yet a last idea was to tell your reader to leave out posts with certain words for a small period of time. This can come in handy when you haven’t watched the newest episode of Game of Thrones yet, but want to stay connected to your feeds without spoilers.
This year really is the year of the Reader and it’s really exciting. I will continue to work on Leesmap a bit more, and share progress if I make some. Hope you do too!

 Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
Facebook