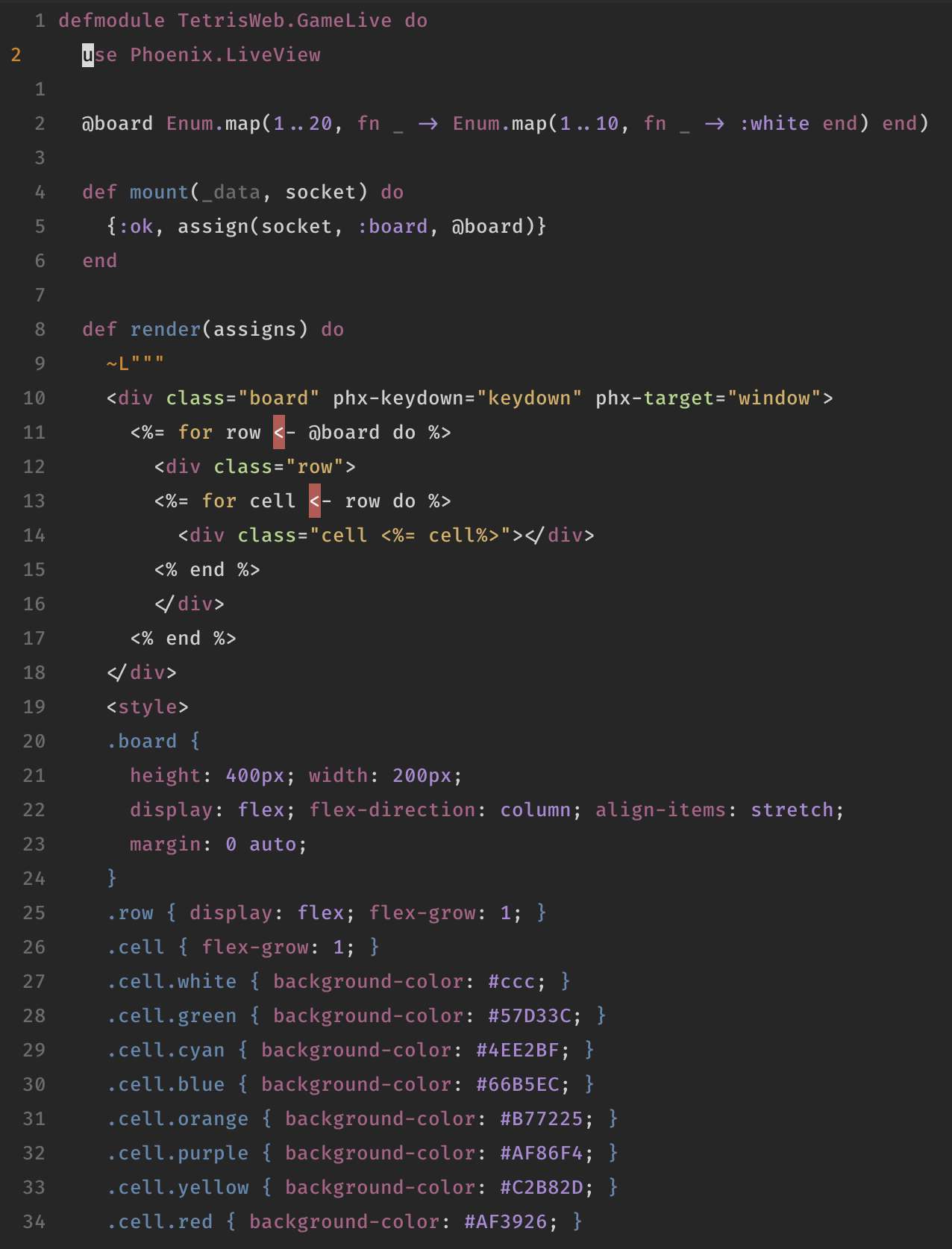
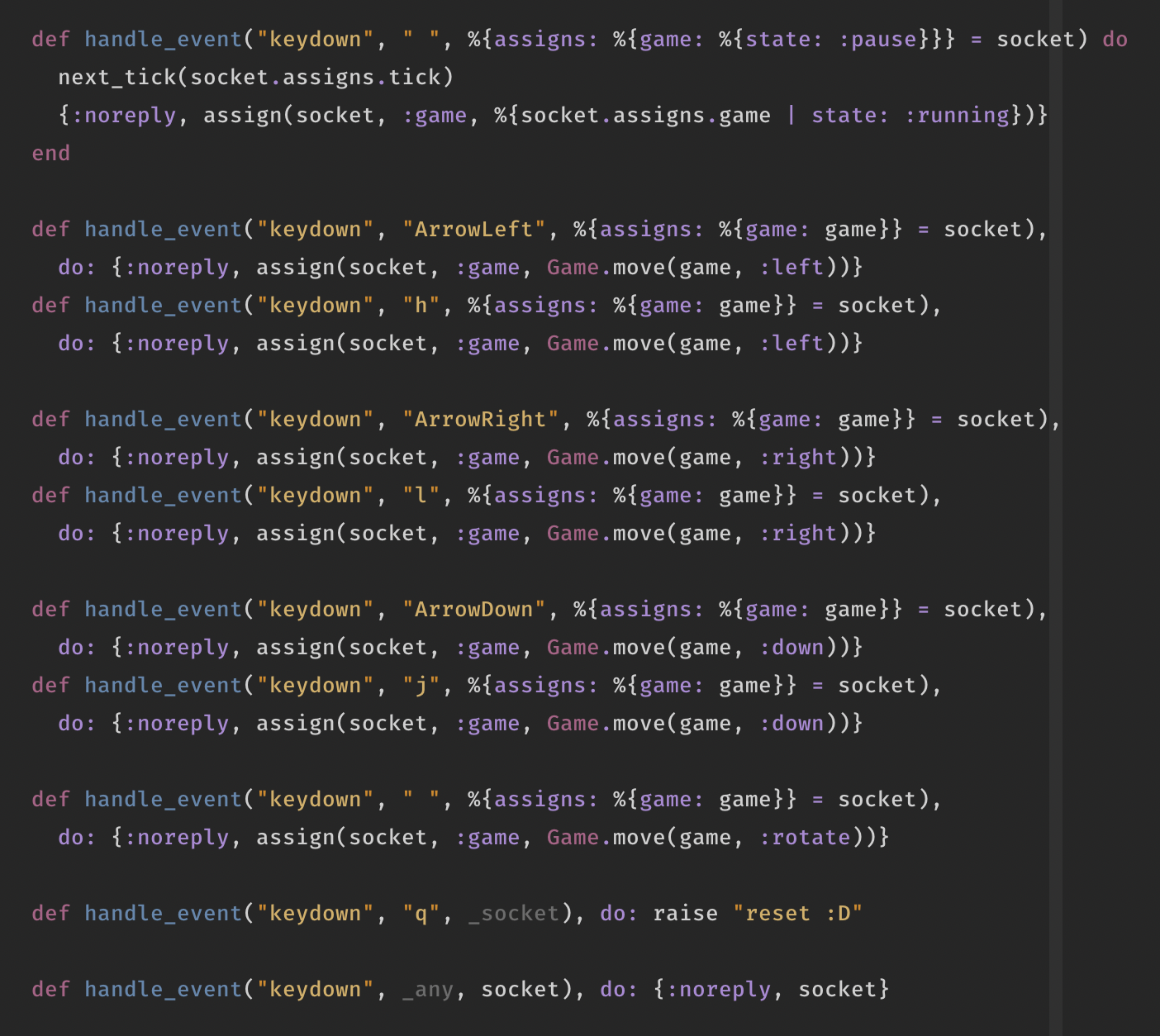
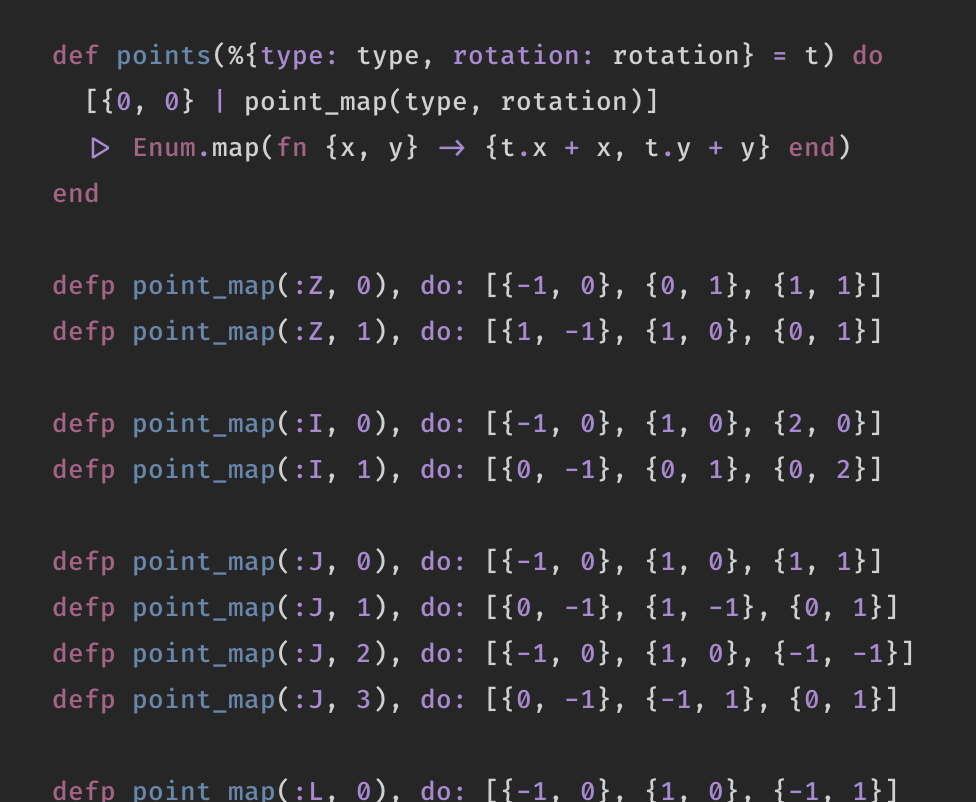
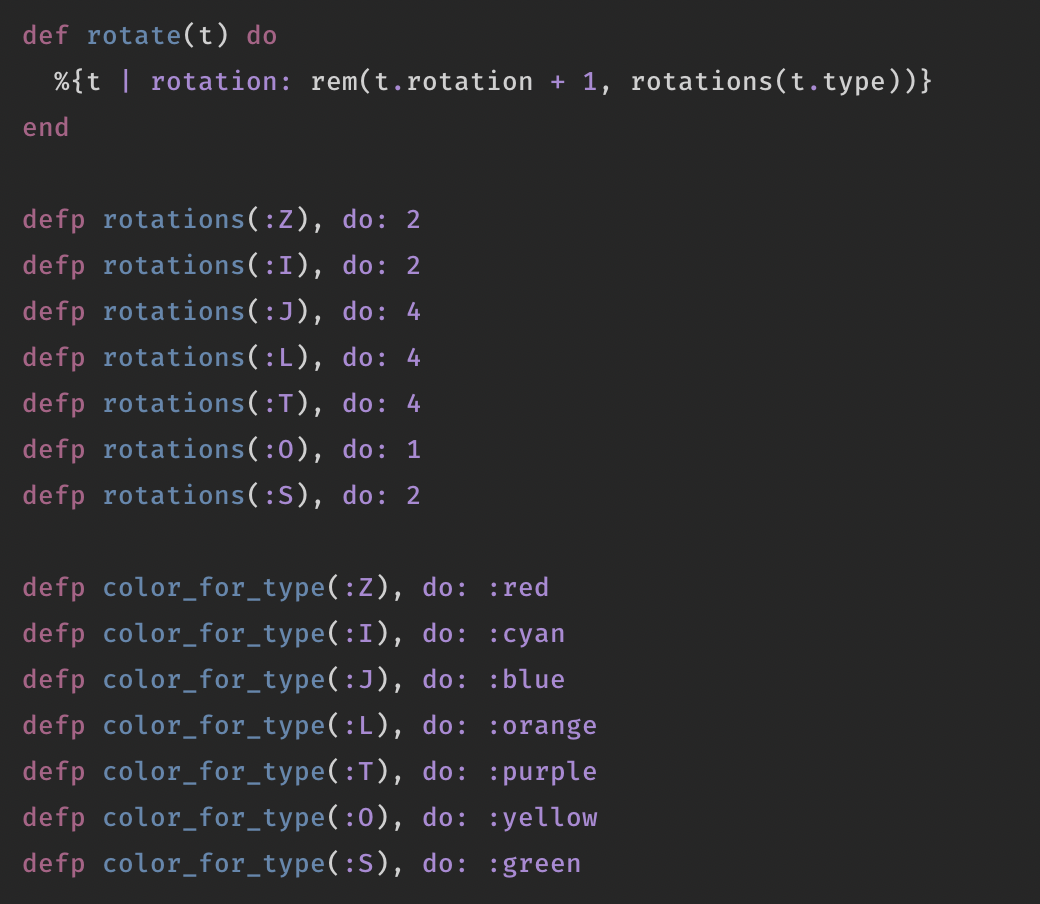
When I started coding around 2005, two questions kept me going: how on earth does a .php file on a server produce a different page if you append ?p=22 to it’s URL; and how do I make my own random generator? The magic of the former now disappeared behind pretty URL schemas (also: there isn’t much depth to it, it turned out), but the latter still catches me from time to time.
Back then, I was intrigued by the site Seventh Sanctum, which was and still is home to many generators. Want a wacky gadget, a quick name, or a wrestling move? One click of a button and you have 15. Heck, I wanted to give three examples so I clicked the ‘random generator’ button three times and it gave me these, like a generator that generates generators.
I made several generators myself, most notably: Randomon, an unfinished and thus empty picture with the height and name of a Poké/Digimon-like creature; the Stamboomgenerator, which draws a wacky family tree with Dutch names and surnames; and various attempts to generate artificial languages. Since I did not know about version control back then I probably lost a lot of it.
Drawing the new city
A few weeks ago, our Dungeon Master Mike showed us the map of the city our characters had just arrived at. It looked awesome: he had drawn roads, walls and it was filled with boxes that represent houses. He’s got time too much, I thought. Also, wouldn’t it be cool if you had a generator that just generates a map like that?
I had been playing with Rust and it’s modular game engine Piston, and you thought: wow, if Rust is really that fast, I can generate a lot of stuff. It ended with me, turning the Hello, World!-example of a spinning red cube into a red cube that could be panned around, with zoom and everything. It’s almost Google Maps, I imagined. Now I just have to make the map.
It was then that the Duck lead me to an article by Amit Patel about generating maps from noise. And then that lead me to his brilliant explanation about noise and just all the rest of his site.
See, back in the day, I quickly discovered that random is both your friend and your enemy in the game of generators. Too much randomness makes certain properties unbelievable. Also, I wasn’t very good at writing and thinking about code back then. The following is literally how the Stamboomgenerator chose how many children a certain family member would have:
$kinderen = array(0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,4,4,5,5,5,5,5,5,6,6,6,6,6,7,7,7,7,8,8,8,9,9,10);
$kinderen = $kinderen[rand(0,count($kinderen)-1)];
I tweaked it by hand, by just running it a lot of times, feeling whether or not the proportion would make sense. There is zero math behind it, I’ve studied Dutch literature, you know.
Everything has already been done
Studying the Red Blob Games site, and getting extra info about the terms on other sites and Youtube, I discovered so much more world (and math) behind these generators. Turns out it’s also called ‘procedural generation’, which gives better search results. Everything already exists, but you need the proper name to Google it.
I don’t recall if I found out about Perlin noise before or after finding the Red Blob Games site, but while reading the articles I keep having “oh but you could…”s and “if you just…”s, which are most of the time resolved by just another article that shows you how to do it. And they all come with an interactive example with sliders for you to adjust as to understand it better. It is a crazy treasure to find.
The whole thing made me also wander off into the world of 3D rendering, exploring OpenGL and linear algebra. It resulted in last weekend’s fiddling with Blender and a donut. This is a totally different topic, but that’s also a field where a lot of knowledge is shared around. There is so much to learn.
Generating my own world
I kept thinking about how to combine all the elements of map making with noise with other approaches, that would give me plate tectonics. I would then like to adjust the scale of generation from millions of years to just years and play out a simulation of human influence on that map, as to finally arrive at a generated city with an actual history.
For the history to play out, I need some form of grid system to divide the planet into manageable chunks. Luckily Amit has written about that too. But unlike me, he actually reads mathematics papers about this stuff, and thus knows that it’s impossible to divide a sphere into equal hexagons and stuff. (You need 12 pentagons.)
And then of course, he also did it: he made a thing that makes planets with tectonics. Including an example that renders in your browser, with slider to change some parameters. It is both so cool and so intimidating.
It’s not that I’m discouraged by the knowledge that someone else has already done things I wanted to do. It’s impossible to be original (and also: it’s impossible to exactly copy). But the intimidating part is all the math behind his stuff, and the complete lack of it on my side.
Still, with this knowledge I might just take some shortcuts with the world and go for the simulation path. It has been done, I know, that was what lead me to Perlin noise. There are just so many fascinating aspects of this topic.
Writing this blogpost probably makes it less likely for things happen, but I owe it to people like Amit to also think out loud sometimes, to share what I have found. Maybe more about this in the future.
Oh and by the way, Mike did not draw that map himself, as I found out. ’Ik heb wel wat beters te doen,’ he said laughingly.

 Twitter
Twitter Instagram
Instagram LinkedIn
LinkedIn Github
Github Strava
Strava Facebook
Facebook